花式查询详解
大约 3 分钟数据库技术ElasticSearch
简单查询
GET /kuangshen/user/_search
# 查询的参数体,使用json构建
{
"query": {
"match": {
"name": "狂神"
}
}
}
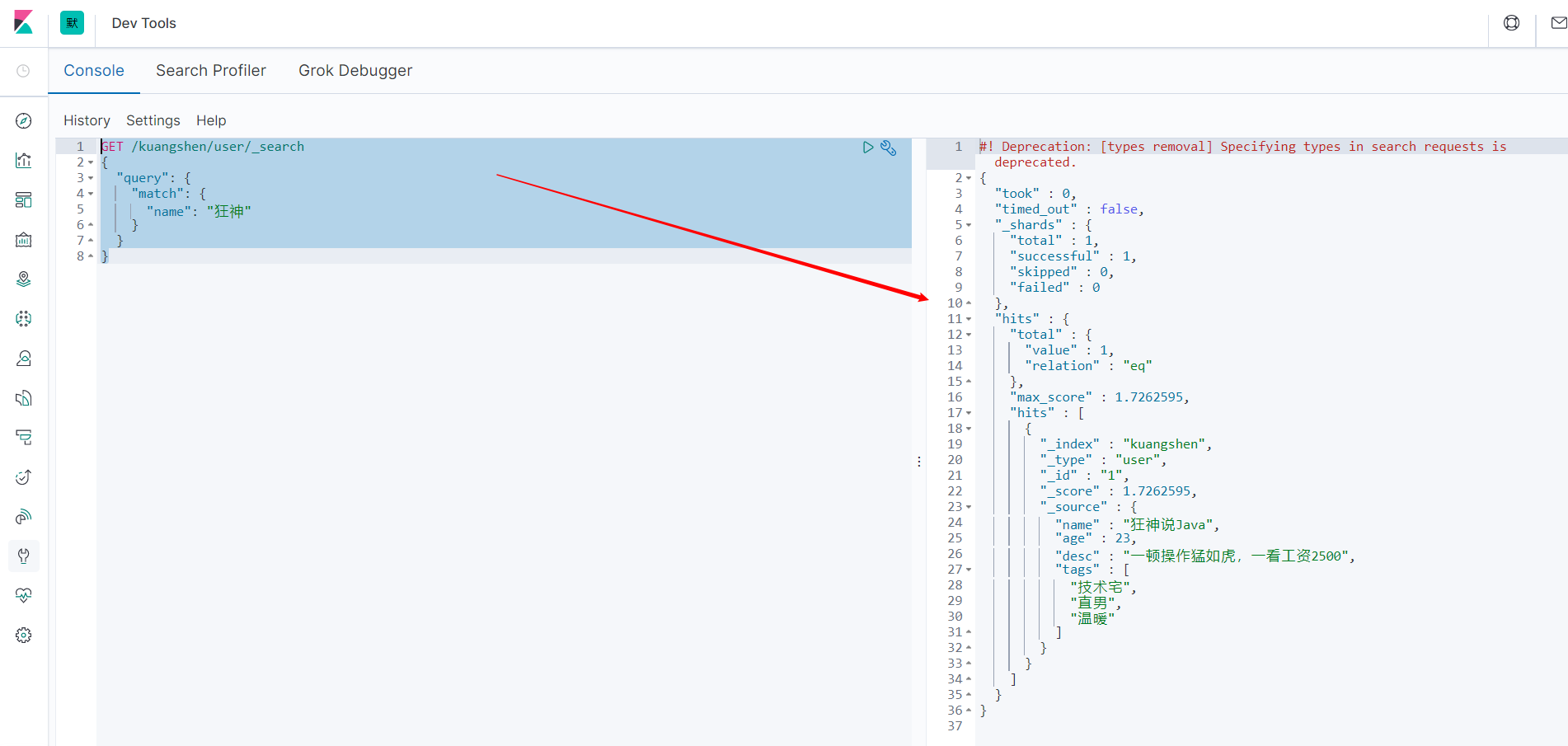
再添加一个4号用户:
PUT /kuangshen/user/4
{
"name": "狂神说前端",
"age": 3,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅","直男","温暖"]
}
再次查询:
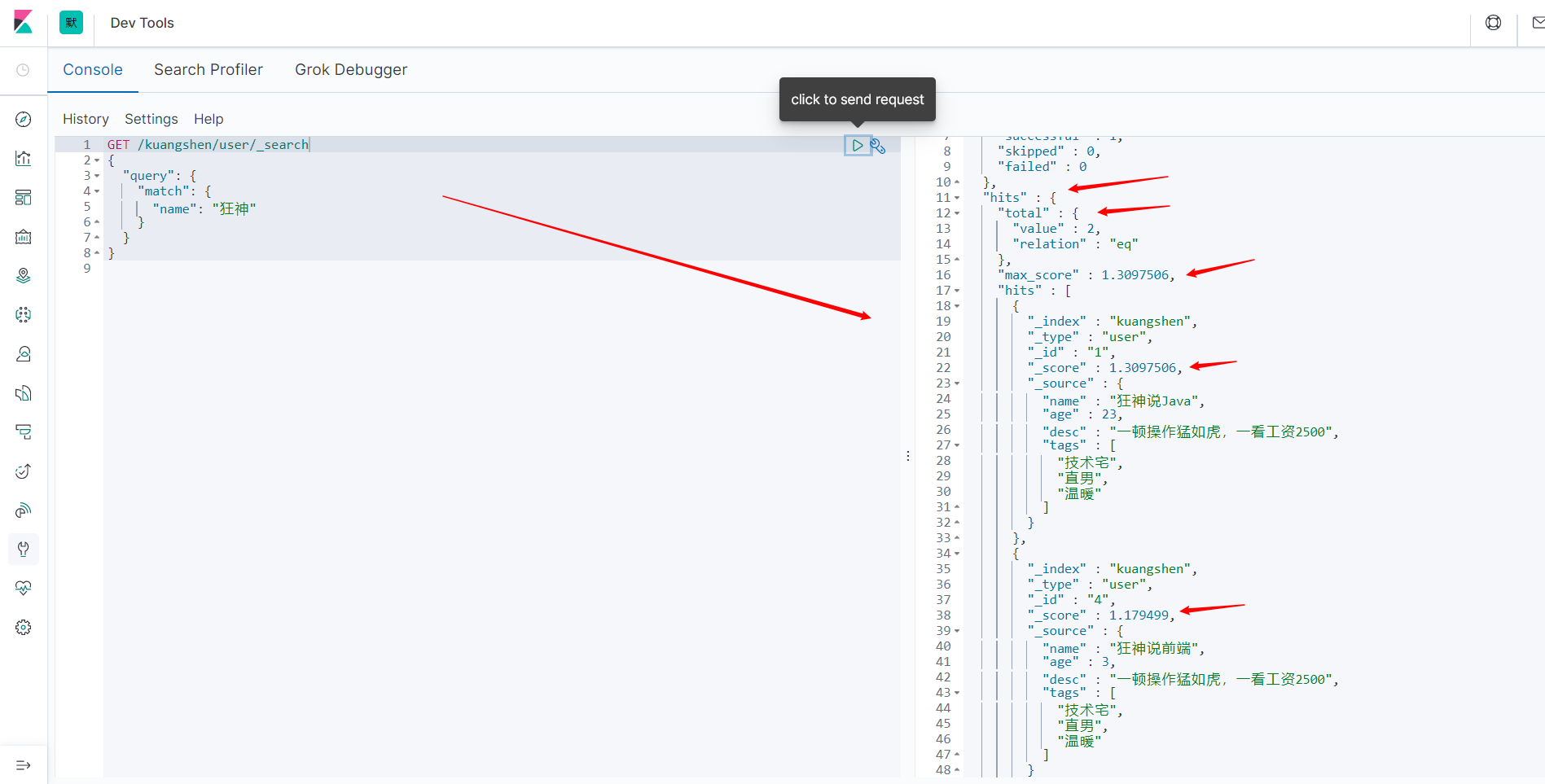
其中hits包含索引和文档的信息。数据中的东西都可以遍历出来。
- 查询结果总数。
- 具体的文档。
- 分数。可以通过判断谁更加符合结果。
结果过滤
GET /kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"_source": ["name", "desc"]
}
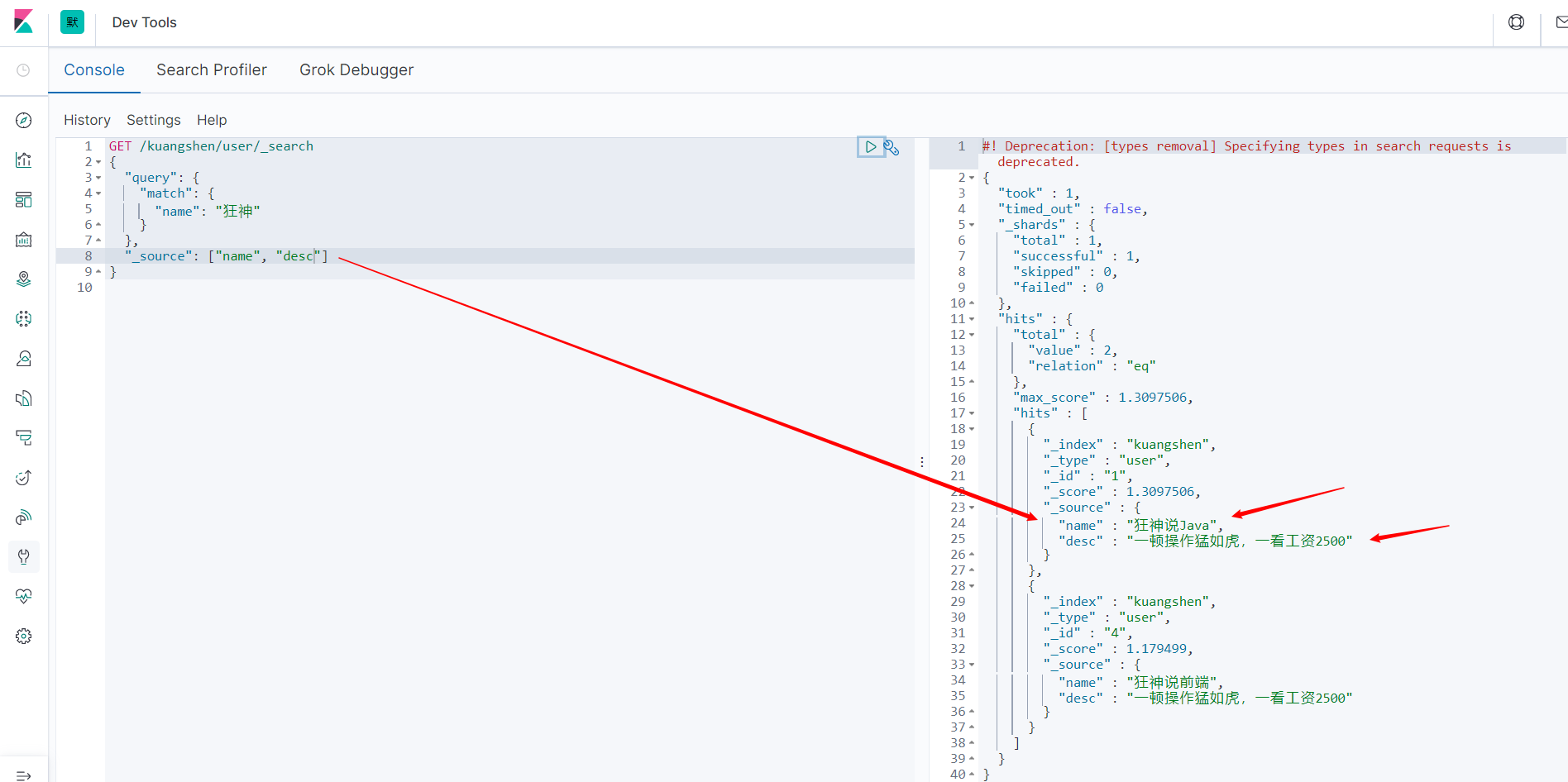
之后使用Java操作ES,所有的方法和对象就是这里面的key。
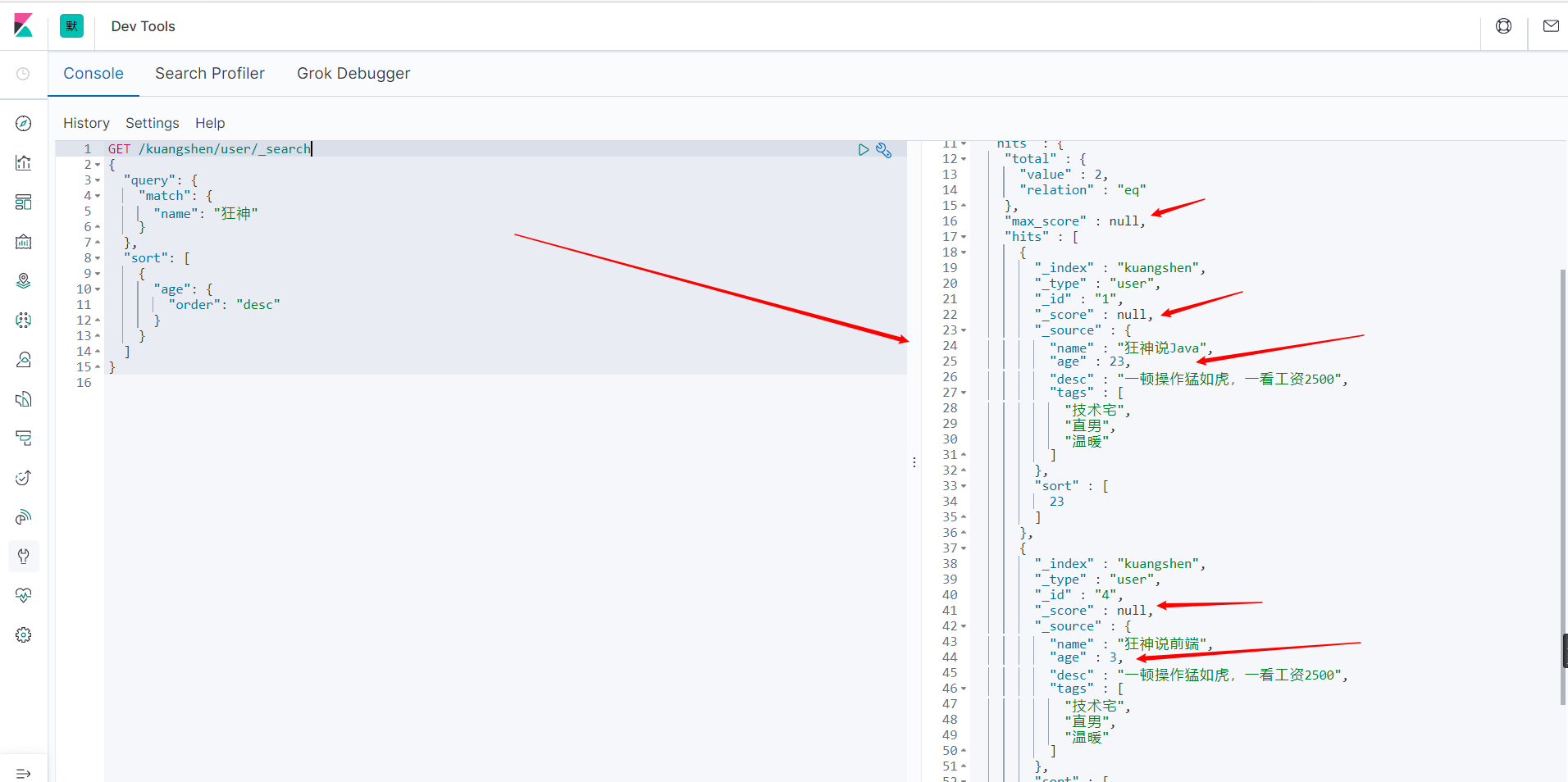
排序
GET /kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"sort": [
{
// 通过哪个字段排序.asc升序,desc降序
"age": {
"order": "desc"
}
}
]
}
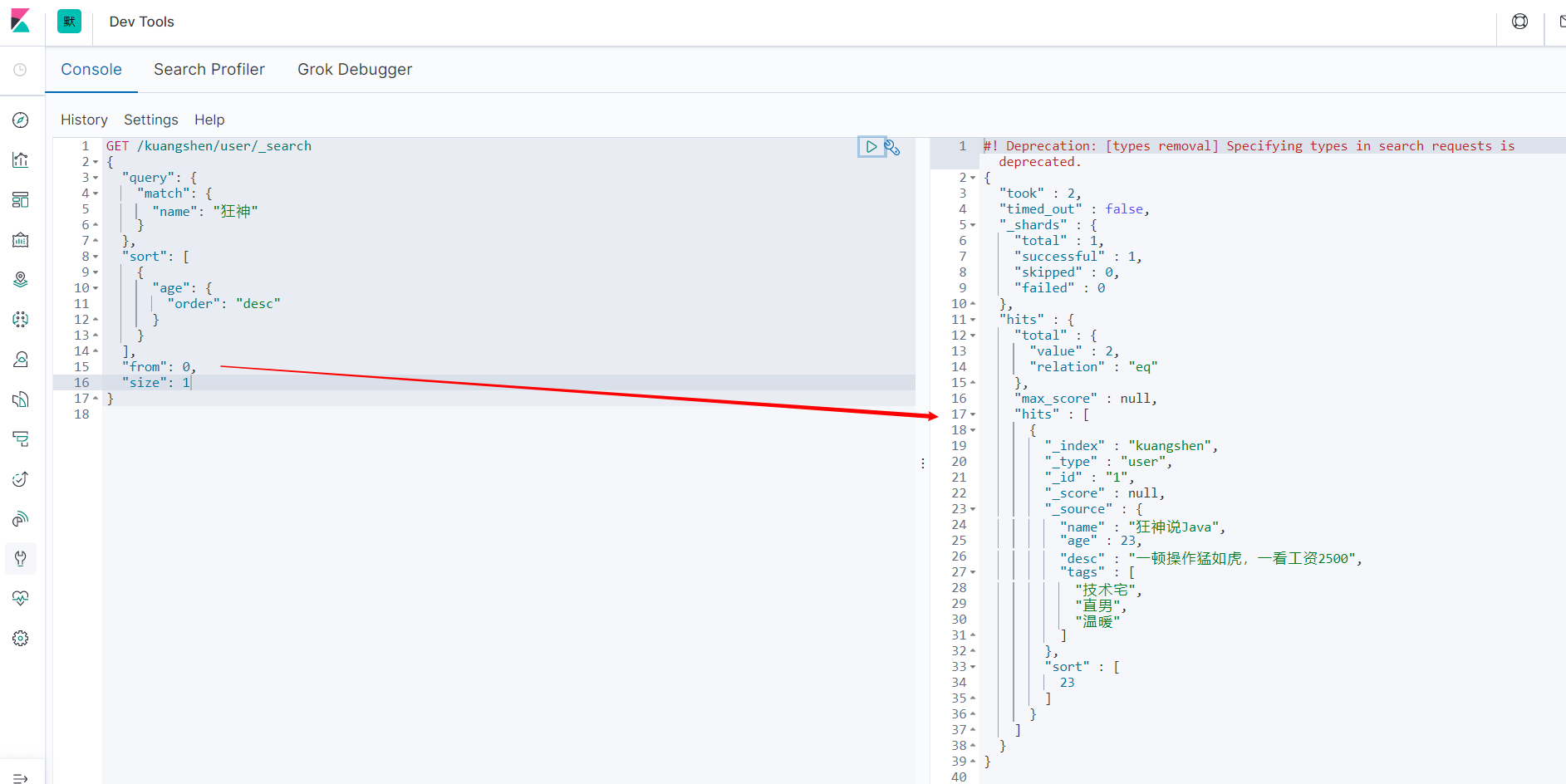
分页查询
GET /kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
// 第几条数据开始
"from": 0,
// 单页数据大小
"size": 1
}
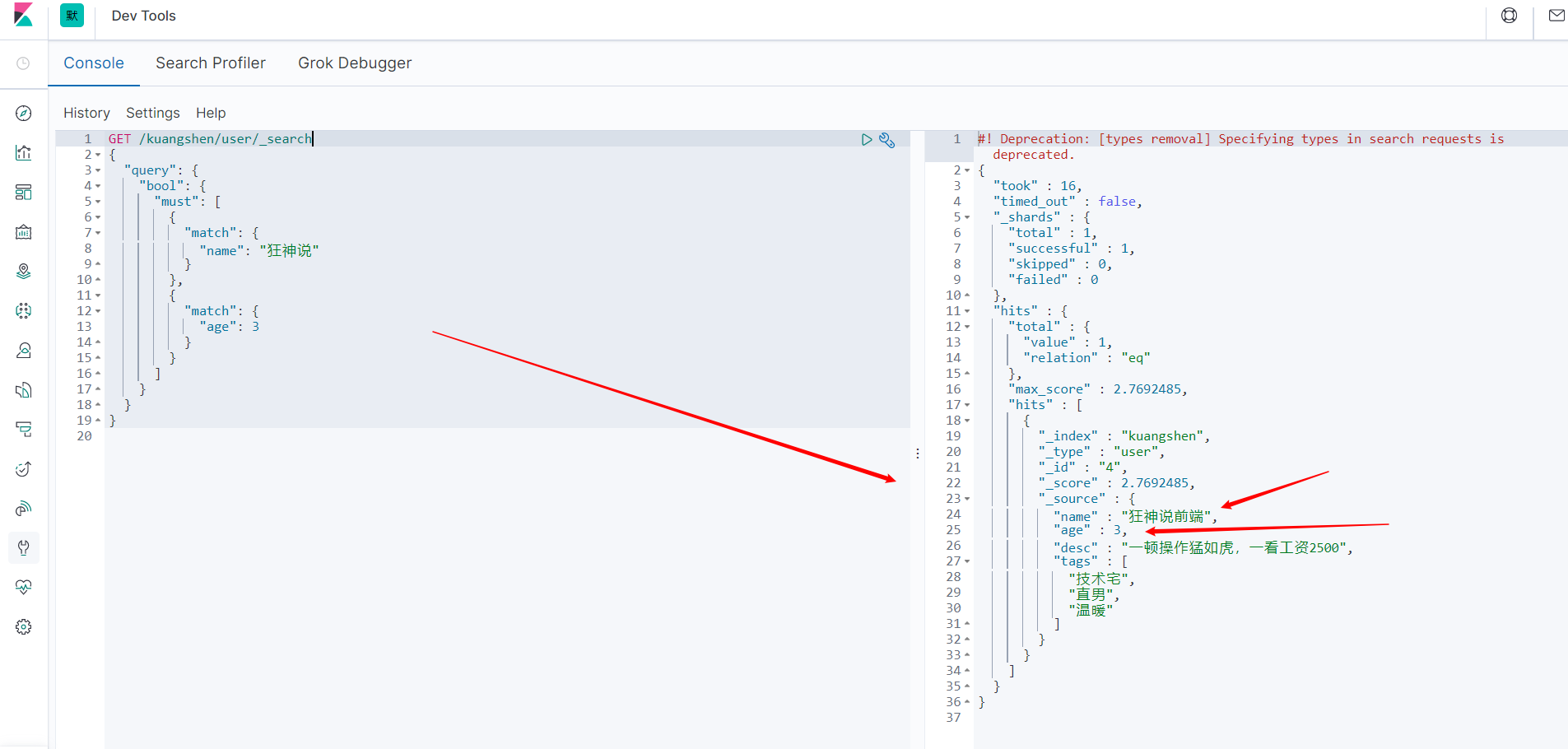
bool值查询
多条件查询:
- must,相当于mysql的and。所有的条件都要符合。
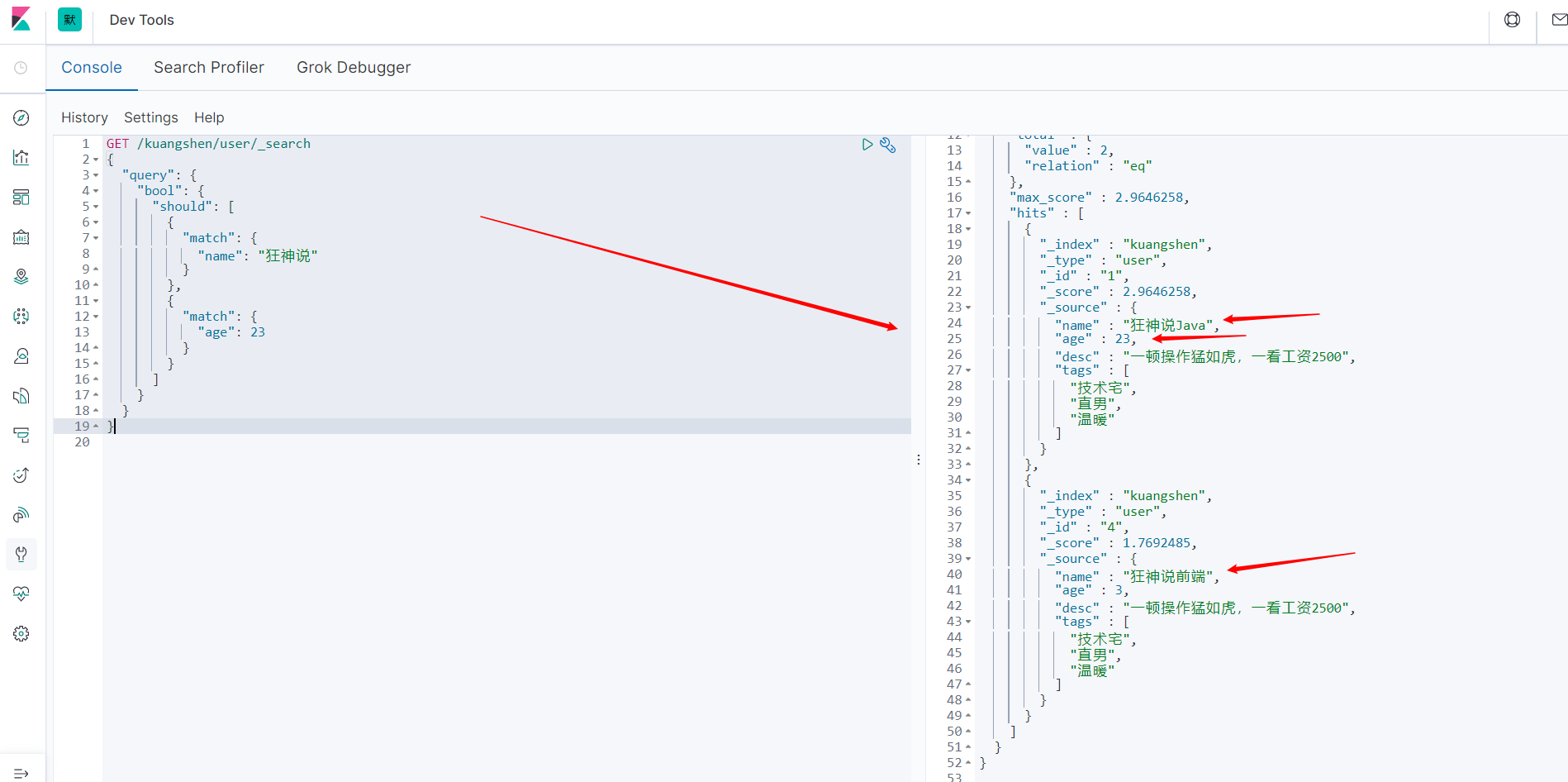
- should,相当于mysql的or。满足其一就符合。
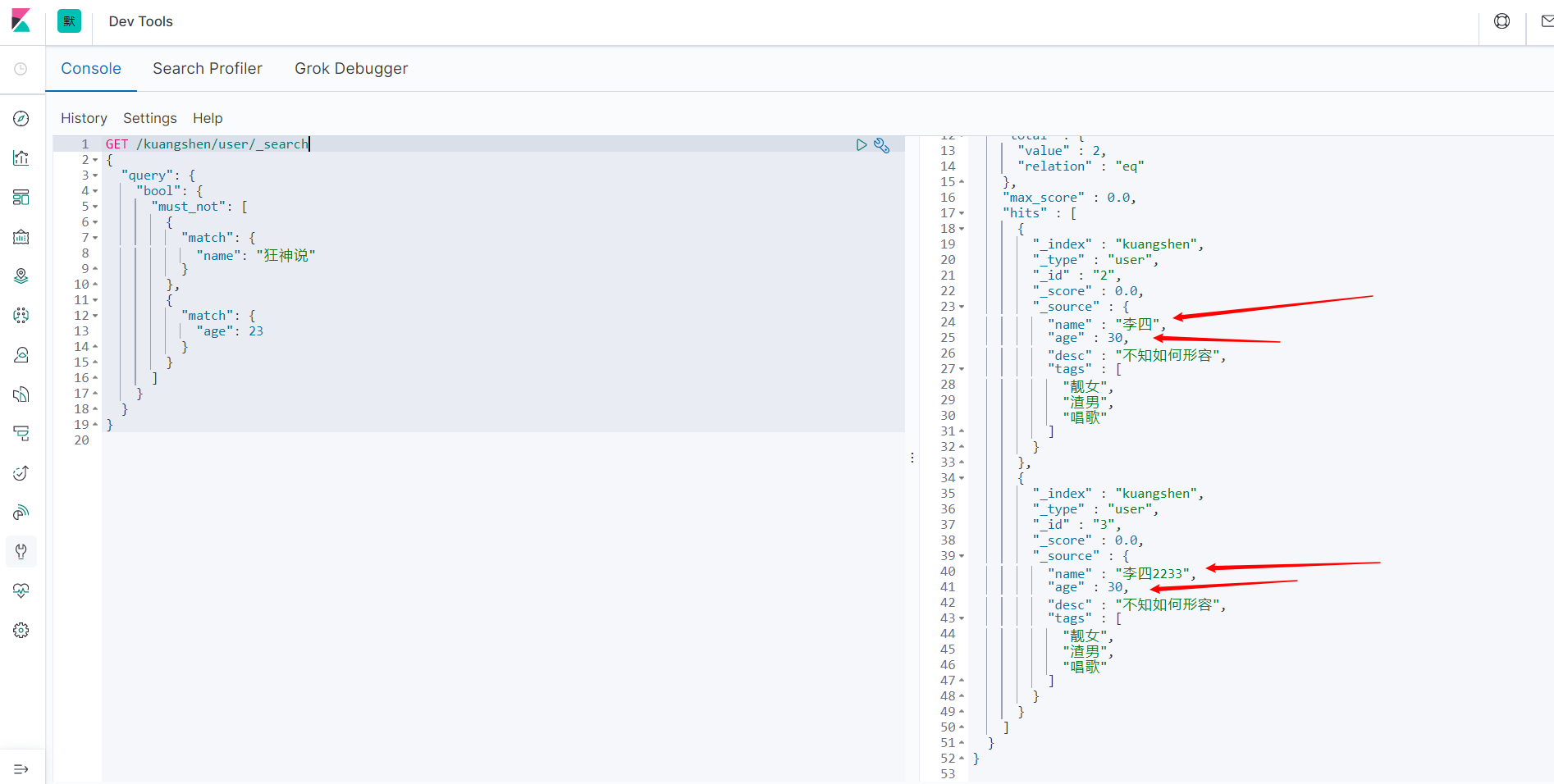
- must_not,相当于mysql的not。全部都不满足。
GET /kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 3
}
}
]
}
}
}
GET /kuangshen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 23
}
}
]
}
}
}
GET /kuangshen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 23
}
}
]
}
}
}
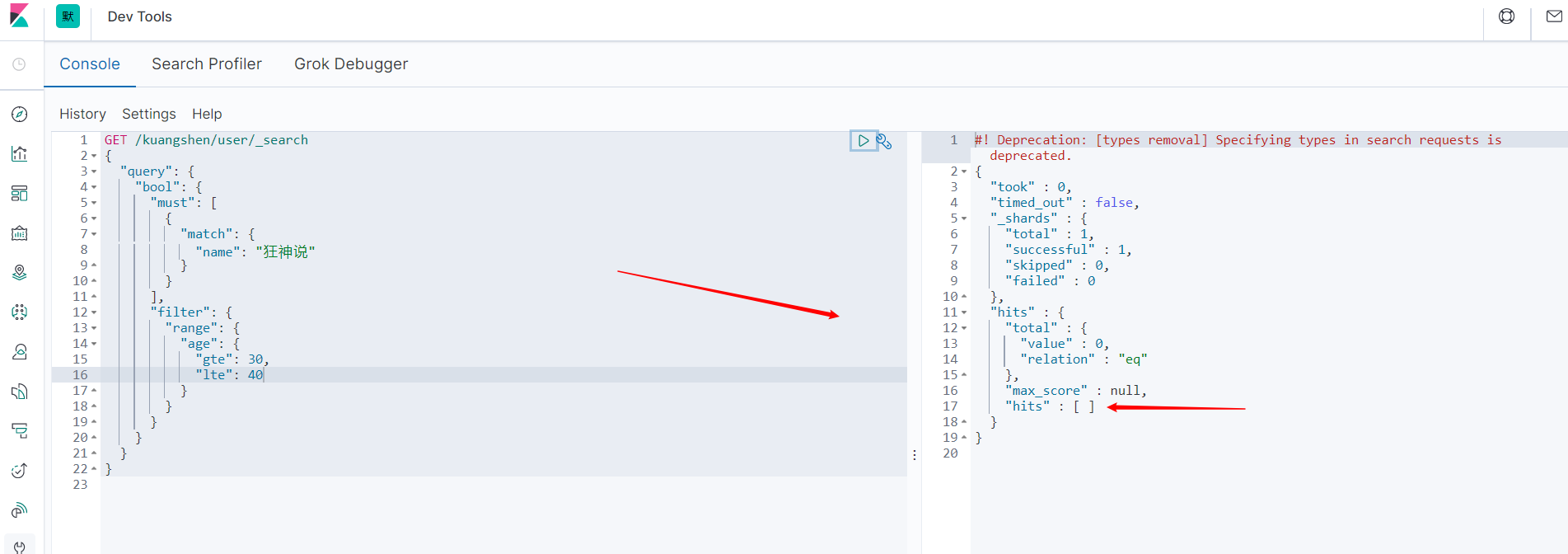
过滤器
使用filter进行数据的过滤。
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
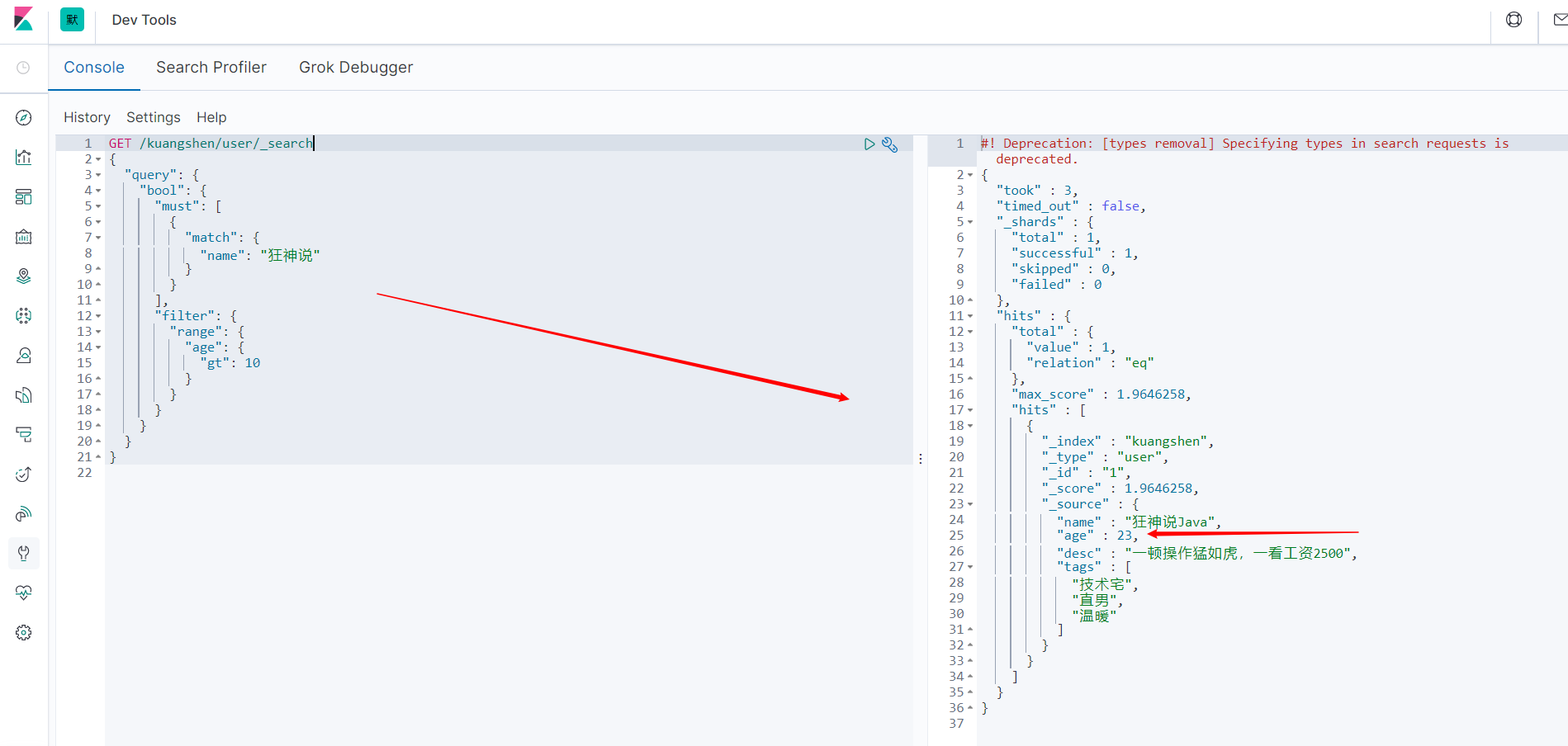
GET /kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神说"
}
}
],
"filter": {
"range": {
"age": {
"gt": 10
}
}
}
}
}
}
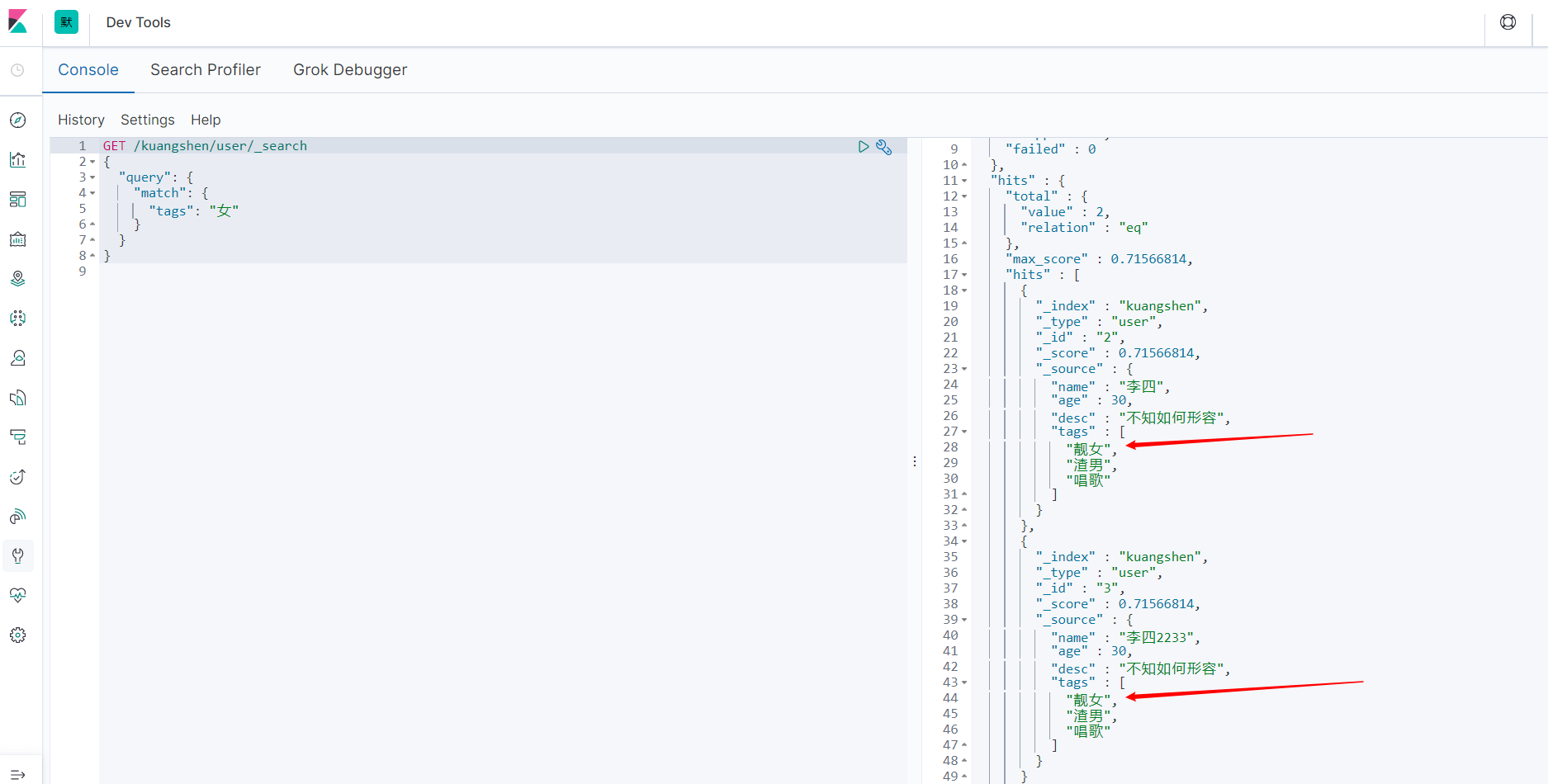
匹配多个条件
GET /kuangshen/user/_search
{
"query": {
"match": {
"tags": "女"
}
}
}
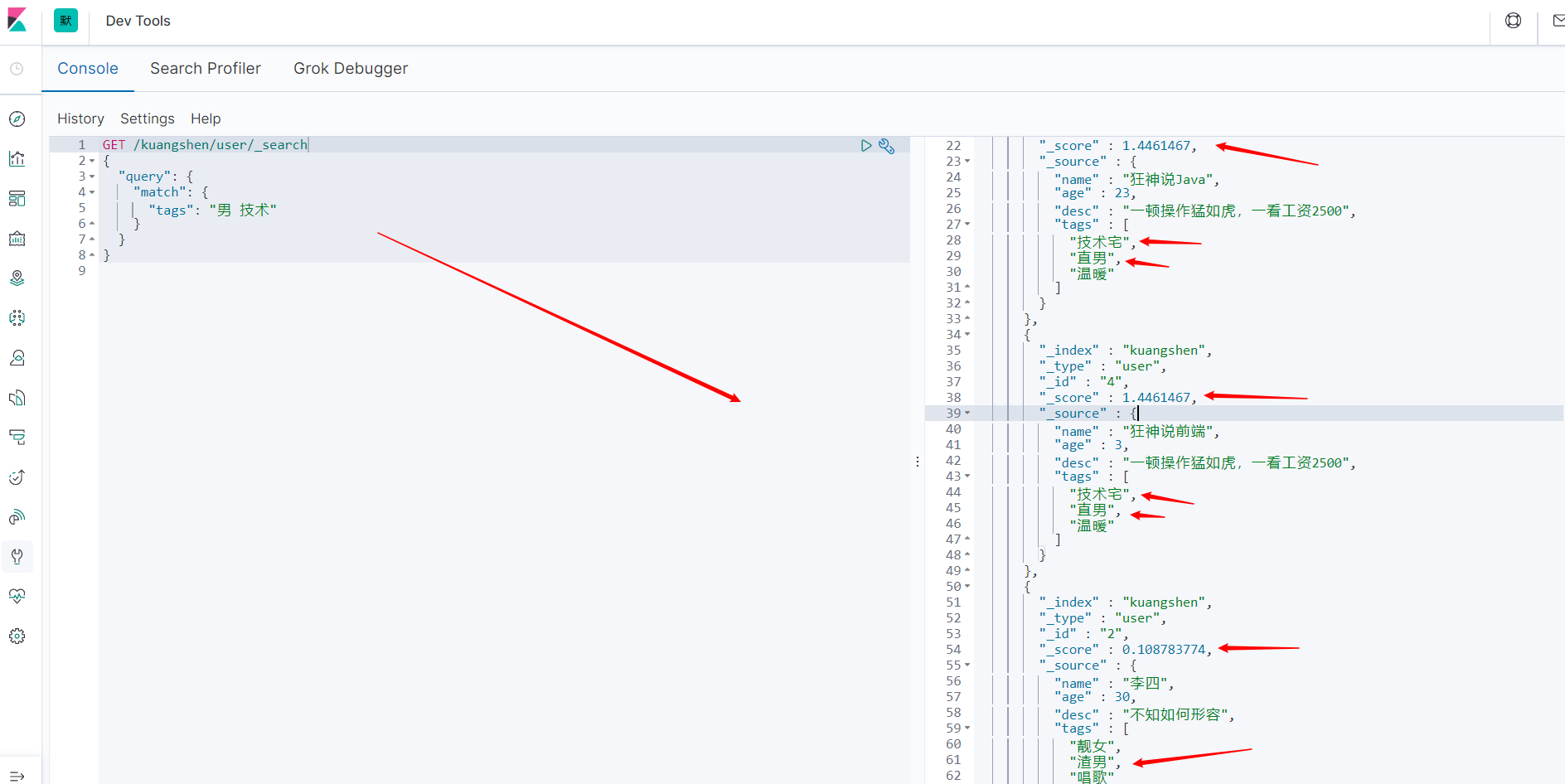
多个条件用空格隔开。主要满足其中一个条件,就会被查出。这个时候可以通过分值进行基本的判断。
GET /kuangshen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
精确查询
term,直接查询精确的值。
match,会使用分词器解析。先分析文档,然后通过分析的文档进行查询。
两个类型
- text会被分词器解析。
- keyword不会被分词器解析。
PUT tesdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
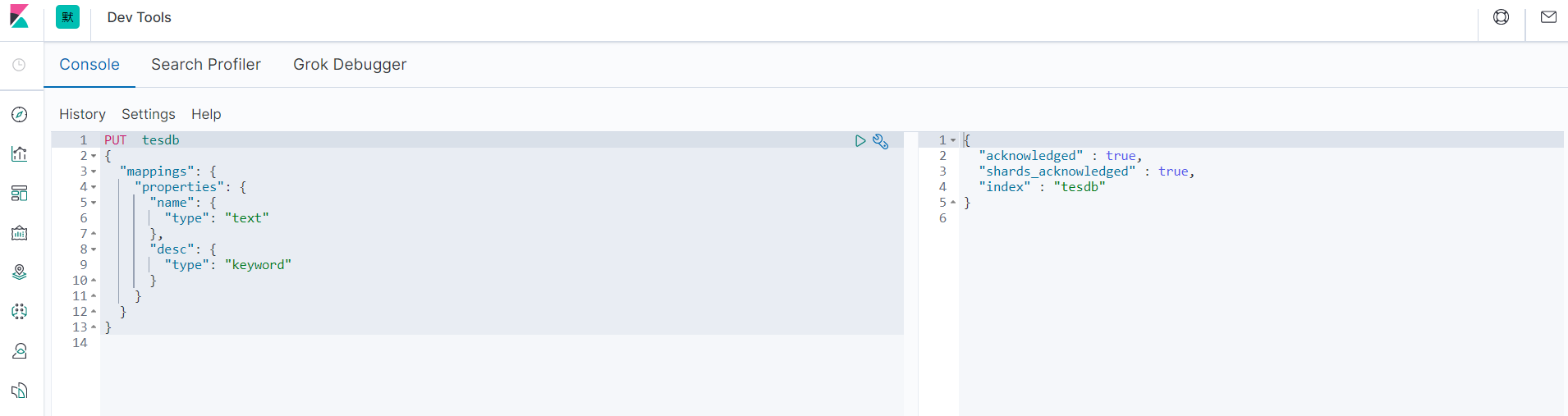
PUT tesdb/_doc/1
{
"name": "狂神说Java name",
"desc": "狂神说Java desc"
}
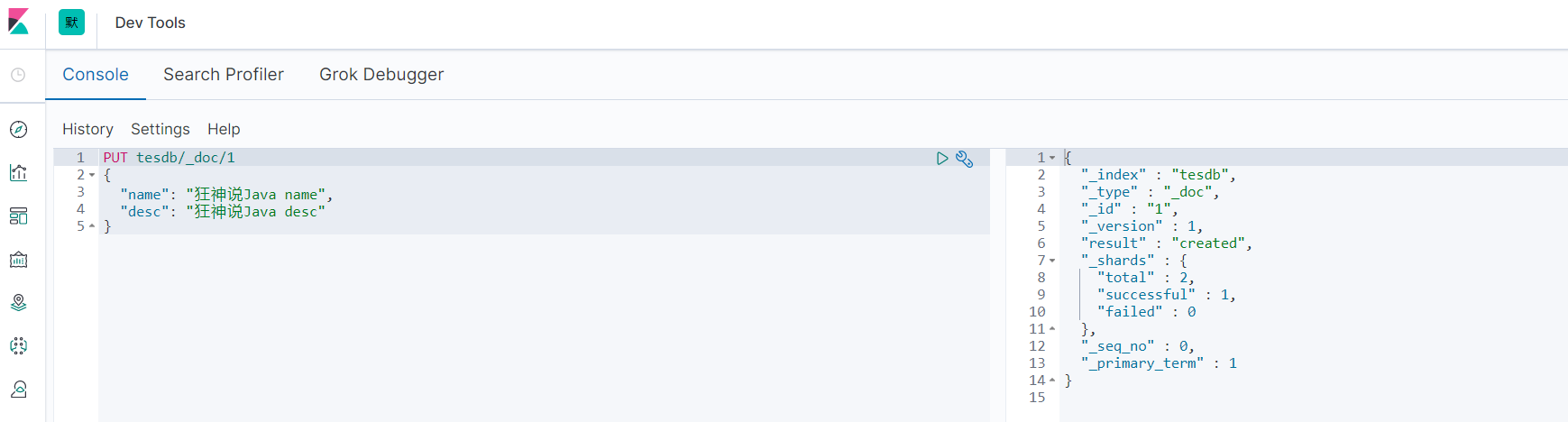
再插入一条:
PUT tesdb/_doc/2
{
"name": "狂神说Java name",
"desc": "狂神说Java desc2"
}
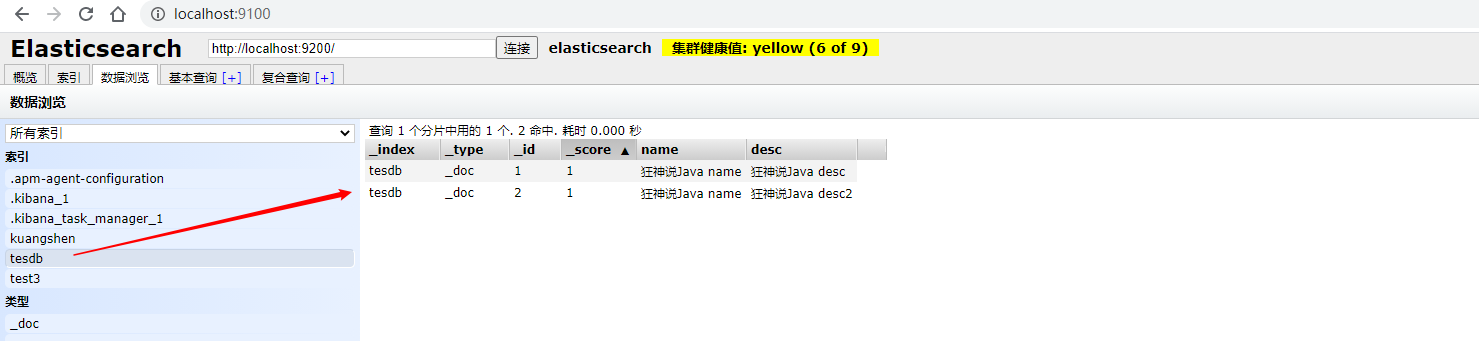
查看head界面:
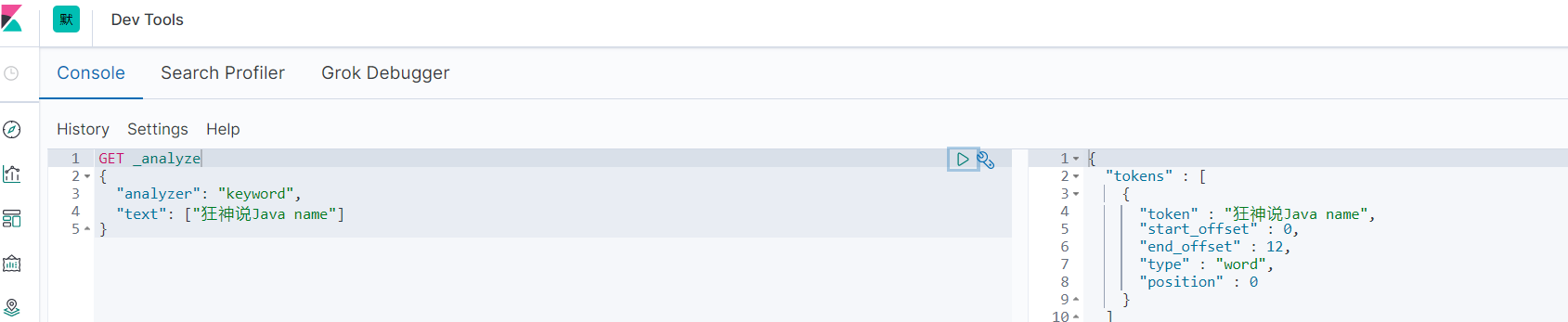
keyword不会被分词器解析
GET _analyze
{
"analyzer": "keyword",
"text": ["狂神说Java name"]
}
GET _analyze
{
"analyzer": "standard",
"text": ["狂神说Java name"]
}
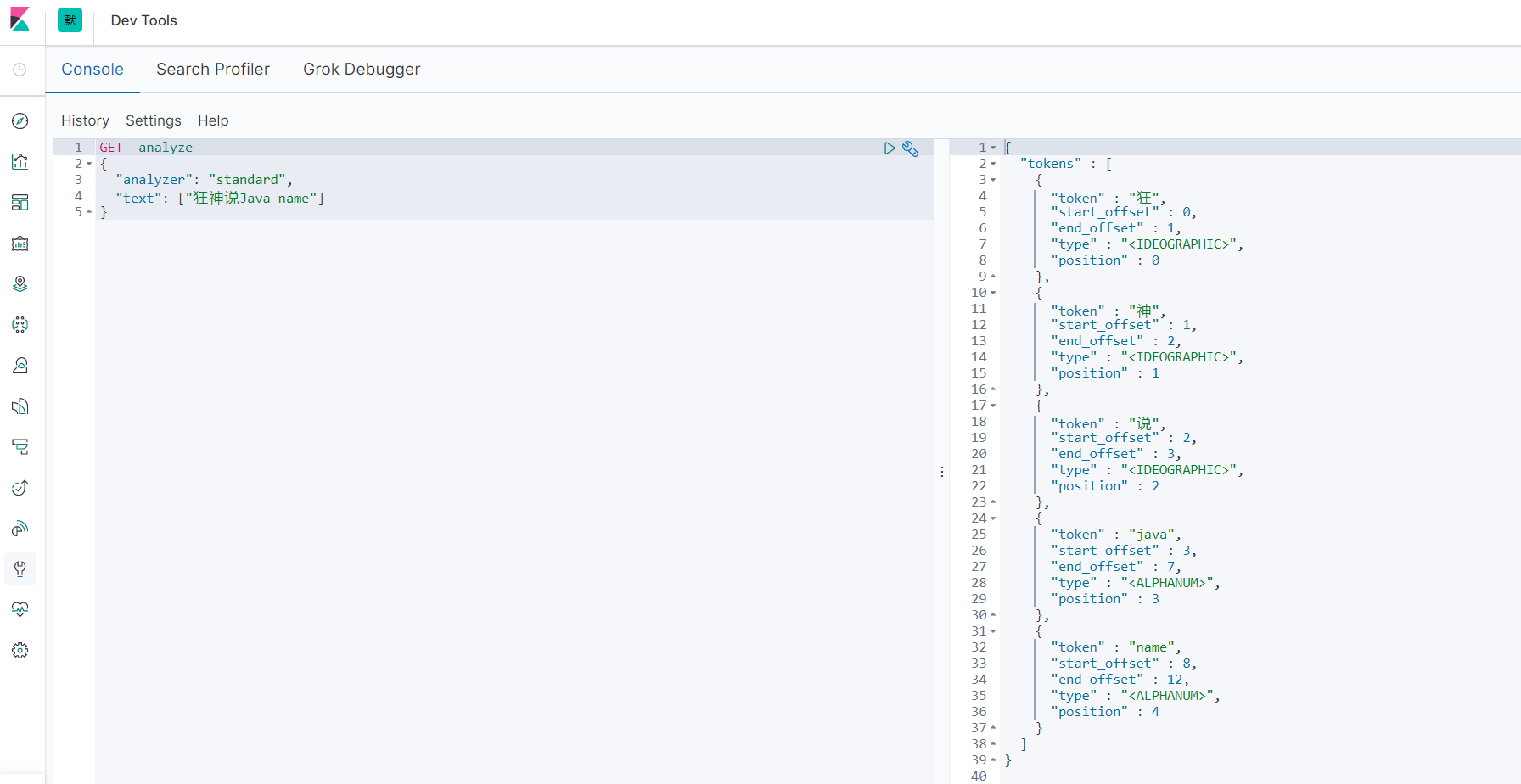
GET tesdb/_search
{
"query": {
"term": {
"name": "狂"
}
}
}
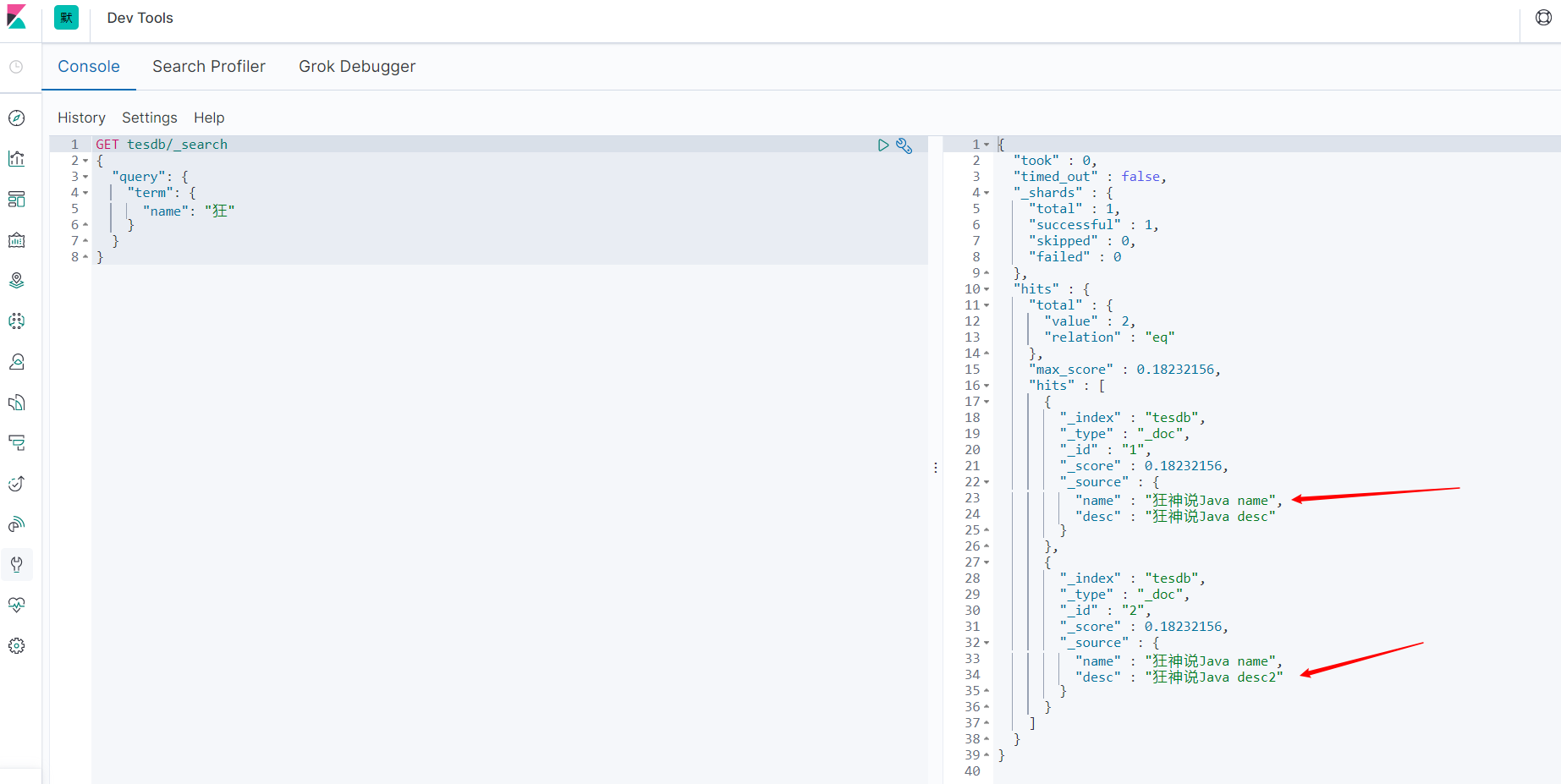
GET tesdb/_search
{
"query": {
"term": {
"desc": "狂神说Java desc"
}
}
}
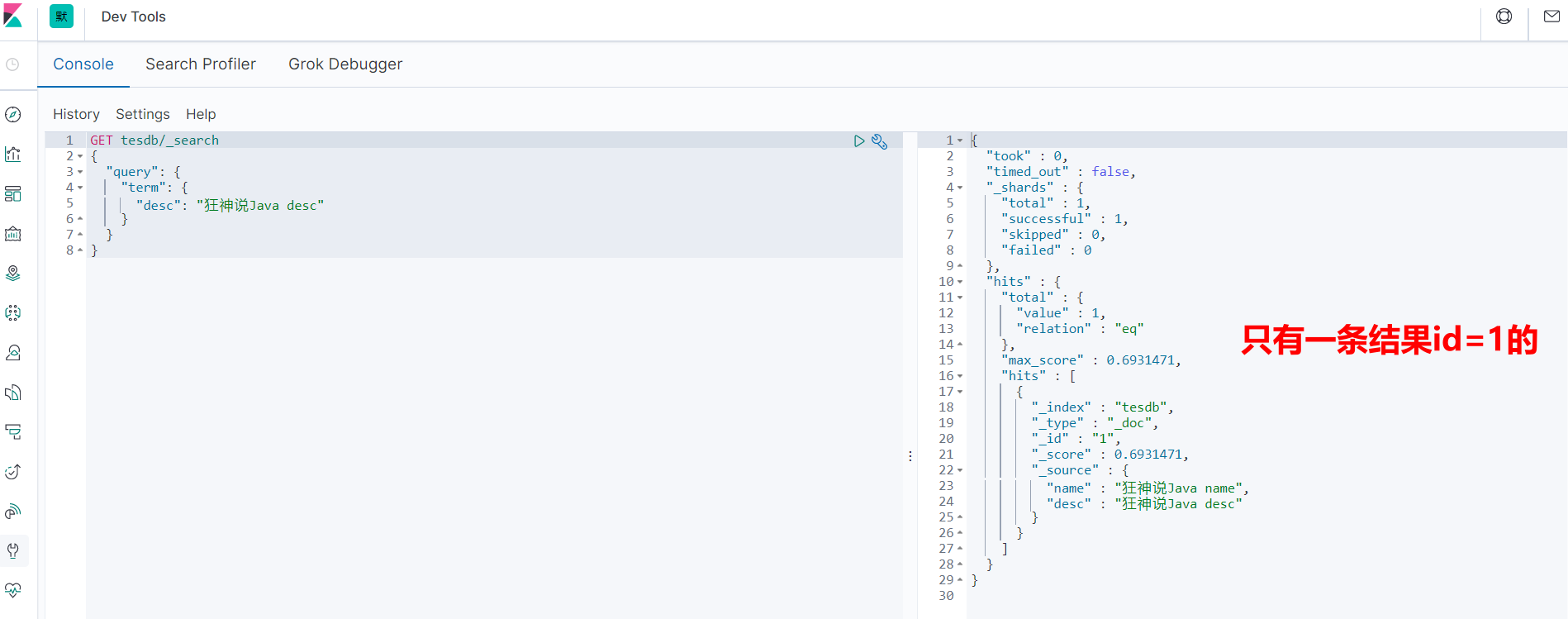
keyword类型的字段不会被分词器解析。
多个值匹配的精确查询
先插入两条数据:
PUT tesdb/_doc/3
{
"t1": "22",
"t2": "2021-03-19"
}
PUT tesdb/_doc/4
{
"t1": "33",
"t2": "2021-03-20"
}
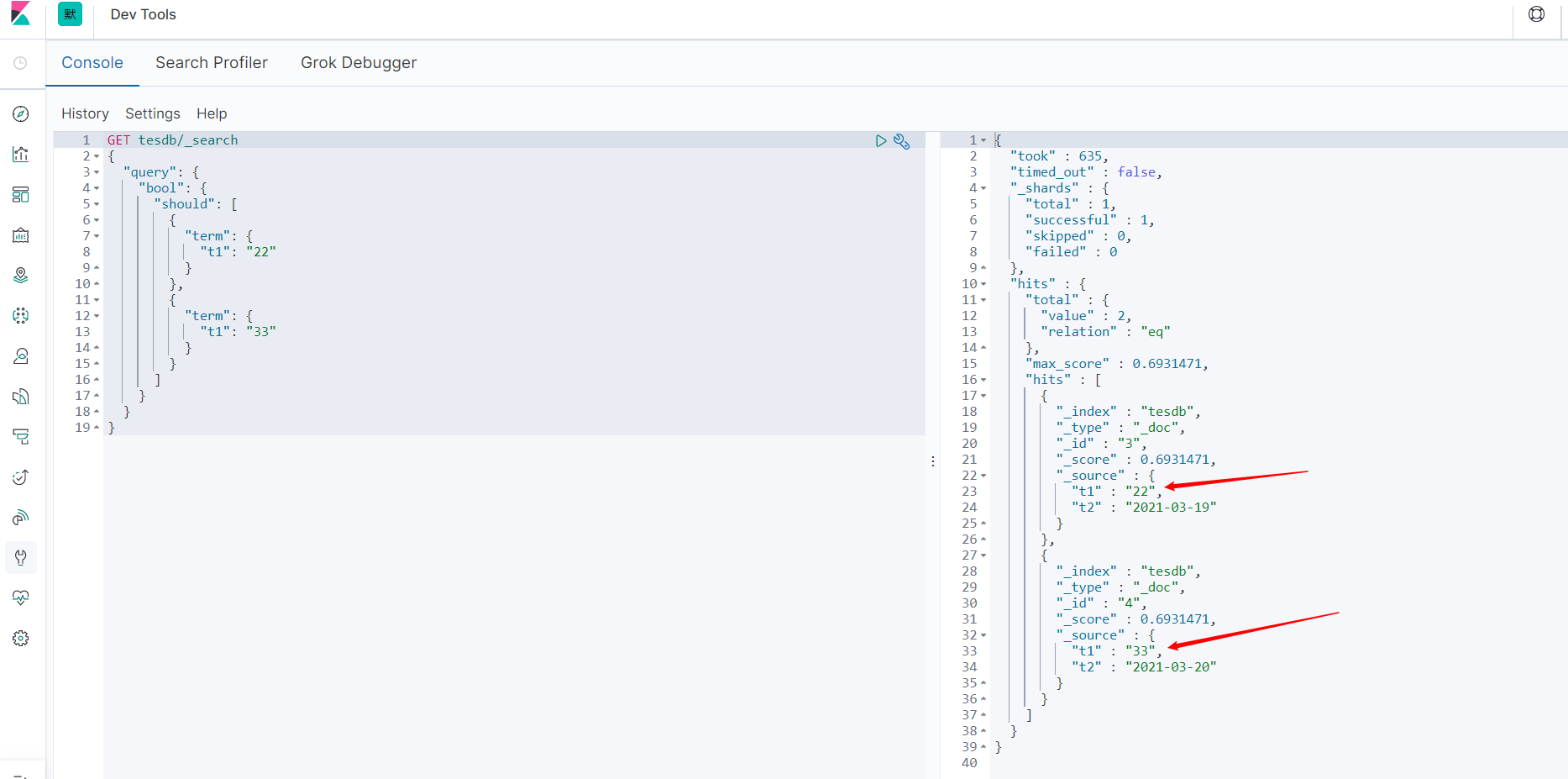
查询:
GET tesdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1": "33"
}
}
]
}
}
}
高亮查询
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
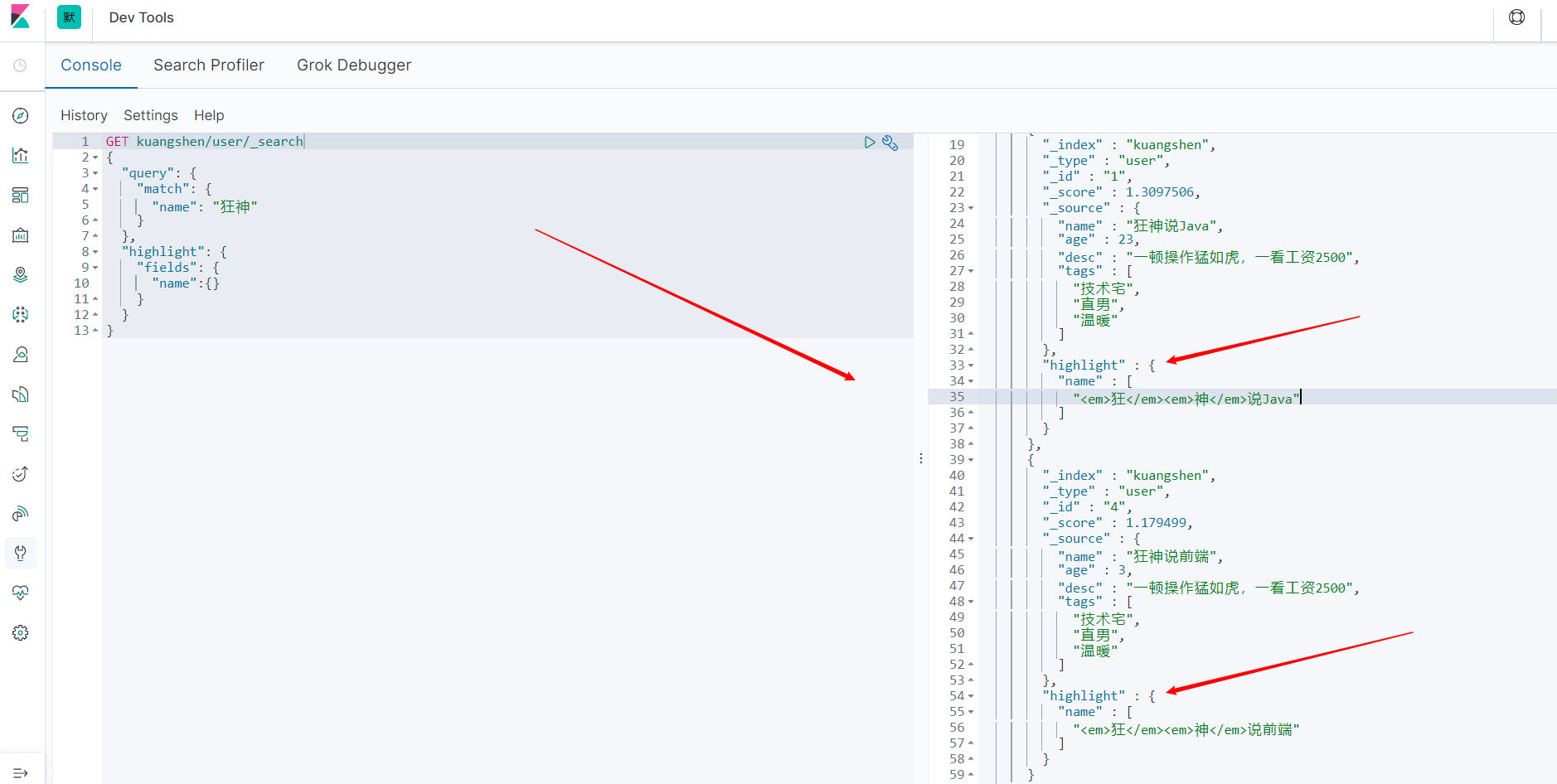
搜索相关的结果可以高亮显示。
自定义高亮标签
GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神说"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name":{}
}
}
}
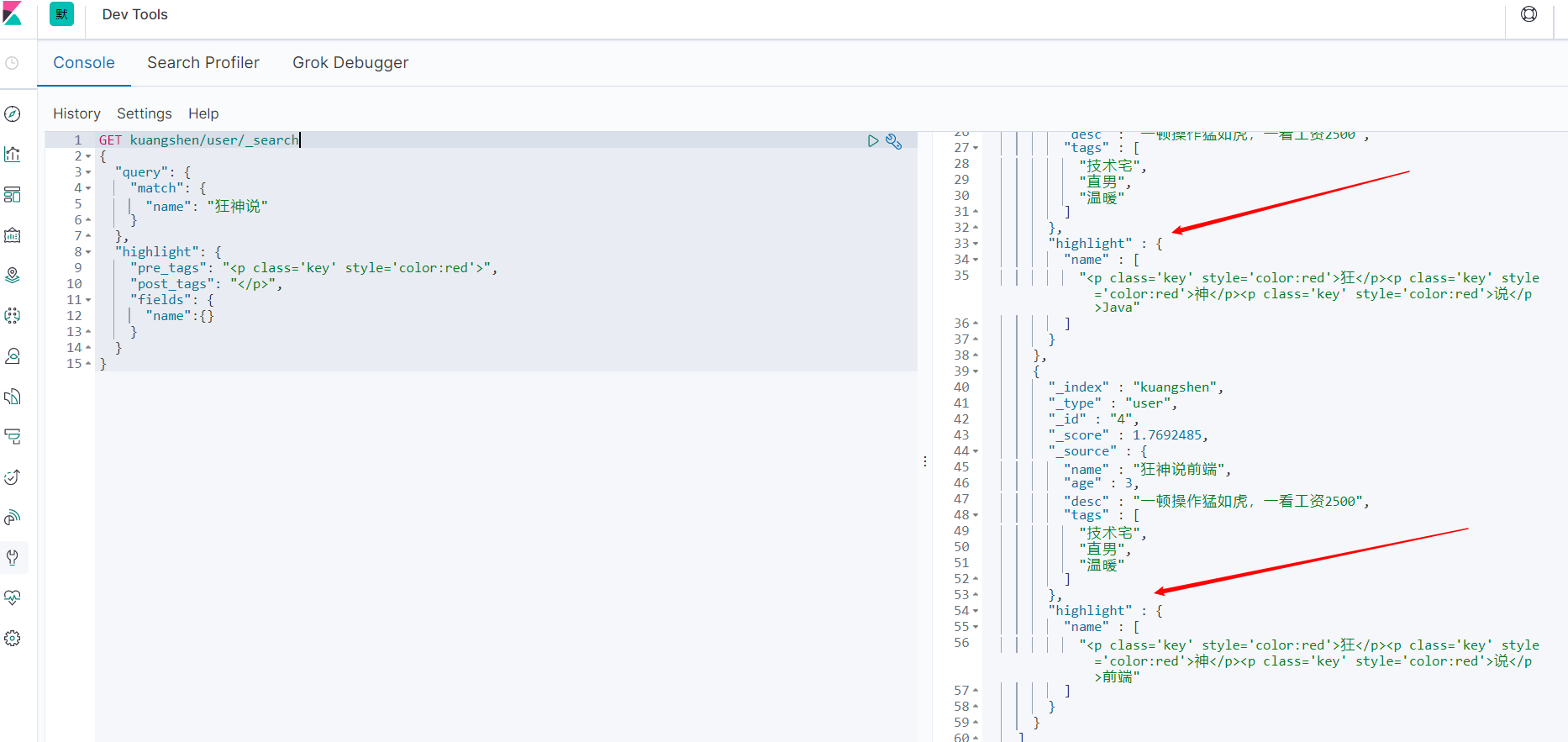
总结
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
这些MySQL都可以做,只是MySQL效率比较低。