IK分词器详解
大约 2 分钟数据库技术ElasticSearch
什么是IK分词器
分词:即把一段中文或者别的划分成一个个的关键字。我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作。默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被为“我"爱”“狂"神” 。这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word ,其中ik_smart为最少切分, ik_max _word为最细粒度划分。
安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
下载完毕之后,解压放入ElasticSearch中的插件目录即可。
重启ES观察,可以看到IK分词器被加载了。

使用elasticsearch-plugin list命令查看加载的插件:

使用Kibana进行测试
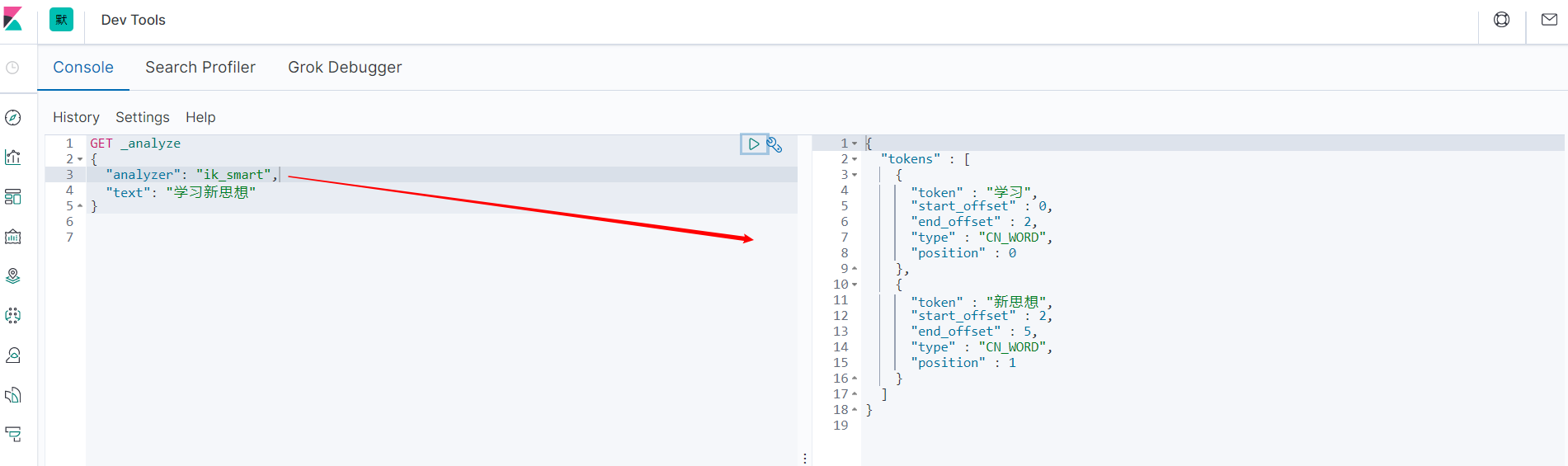
ik_smart 最少切分
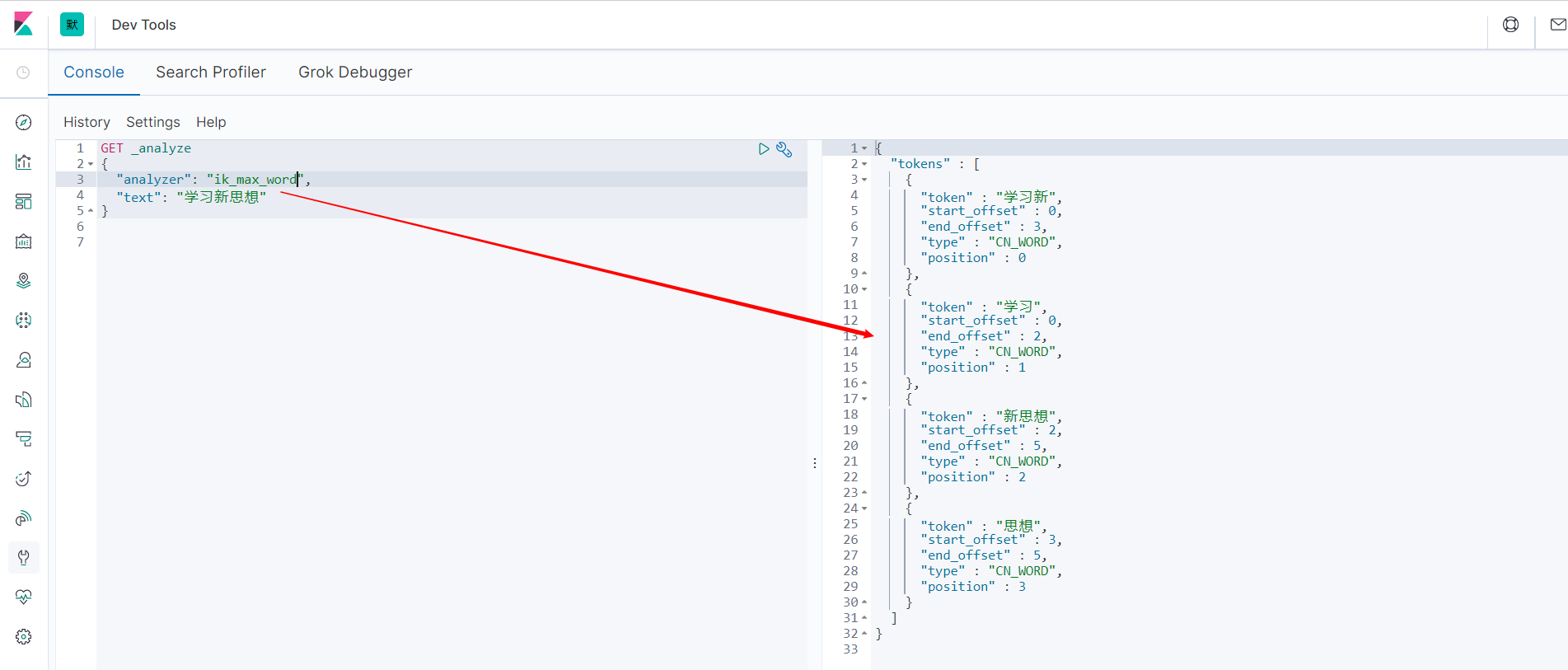
ik_max_word 最细粒度划分。穷尽词库的可能。
字典
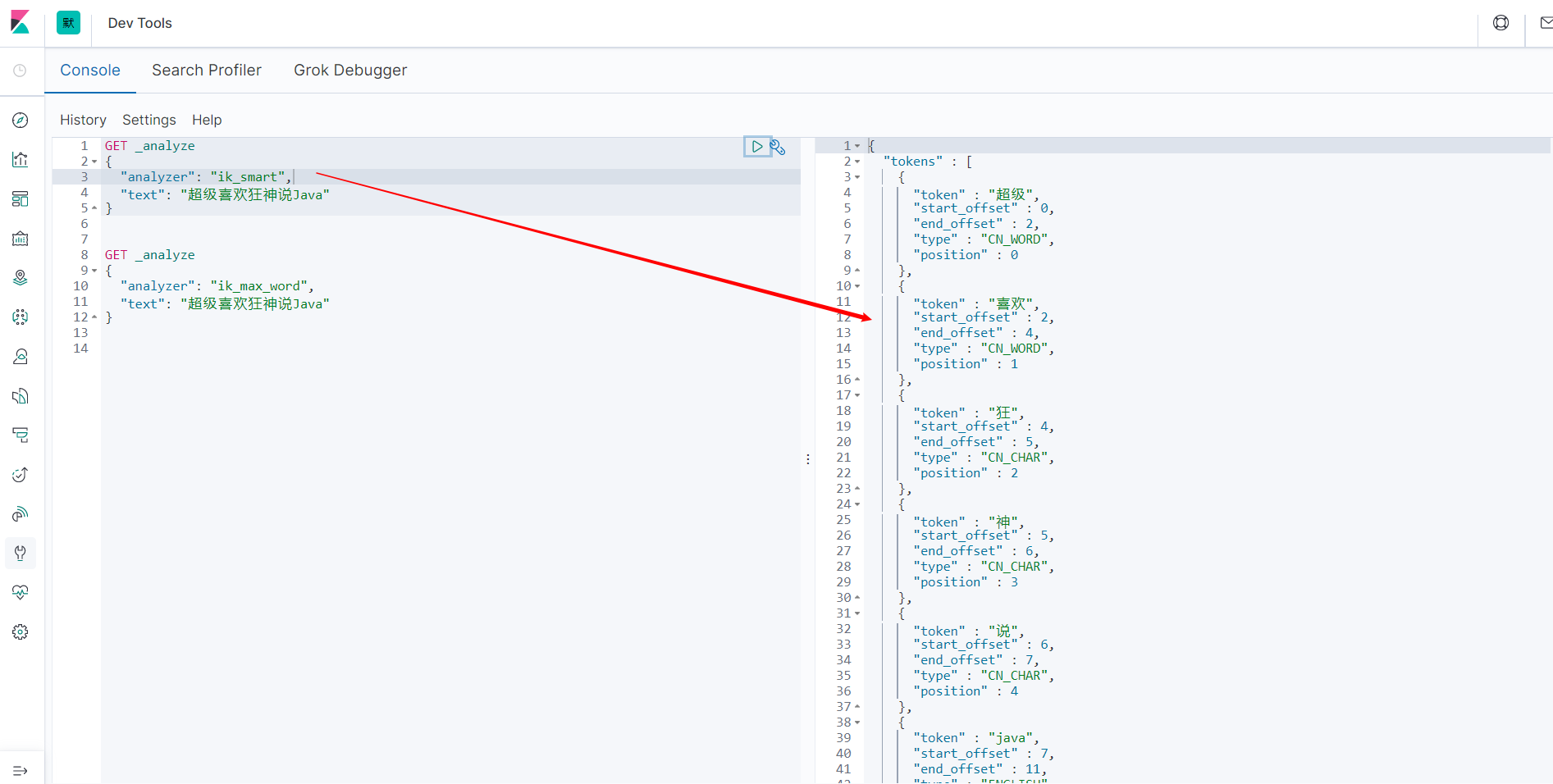
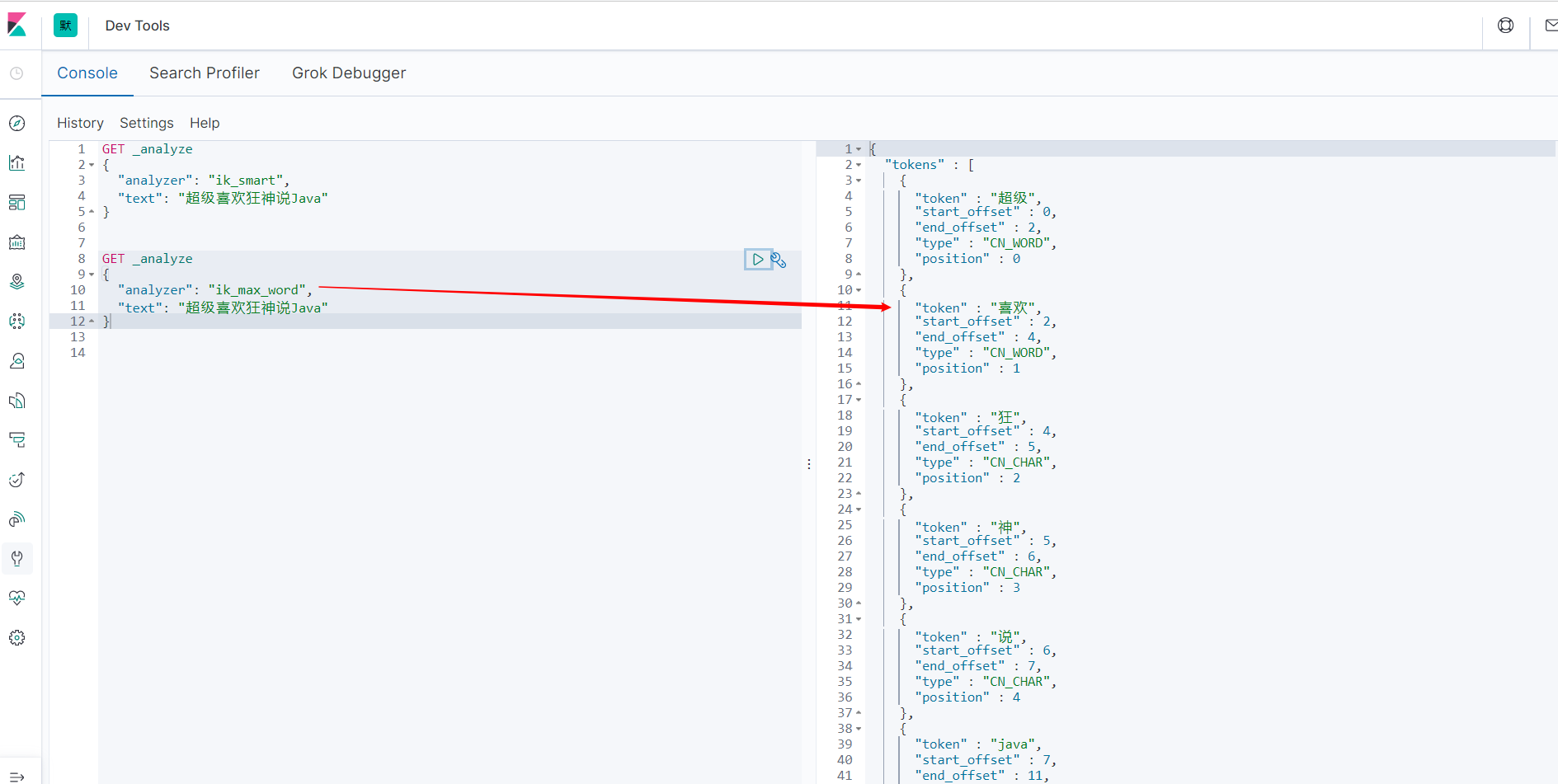
发现问题:狂神说被拆开了。自己需要的词,需要我们自己加到我们的分词器的字典中。
配置自己的字典
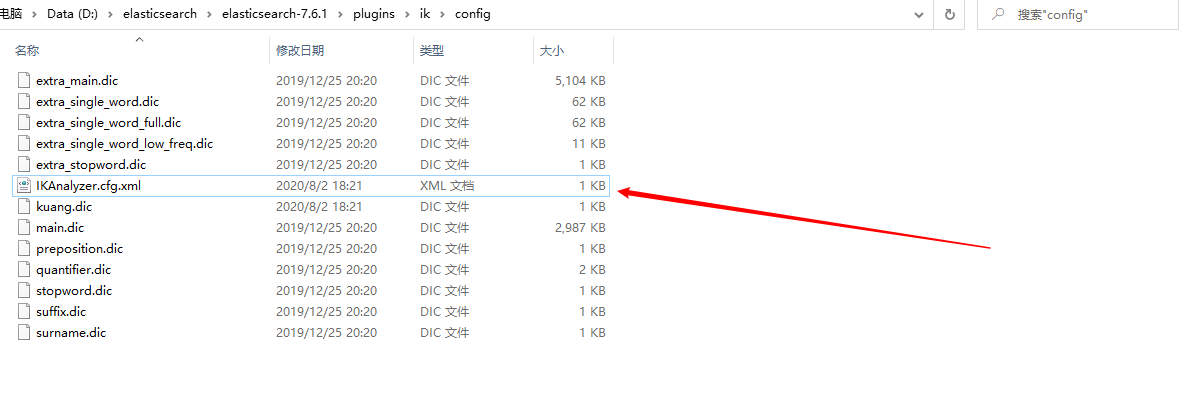
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">kuang.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
kuang.dic
狂神说
重新启动ES:
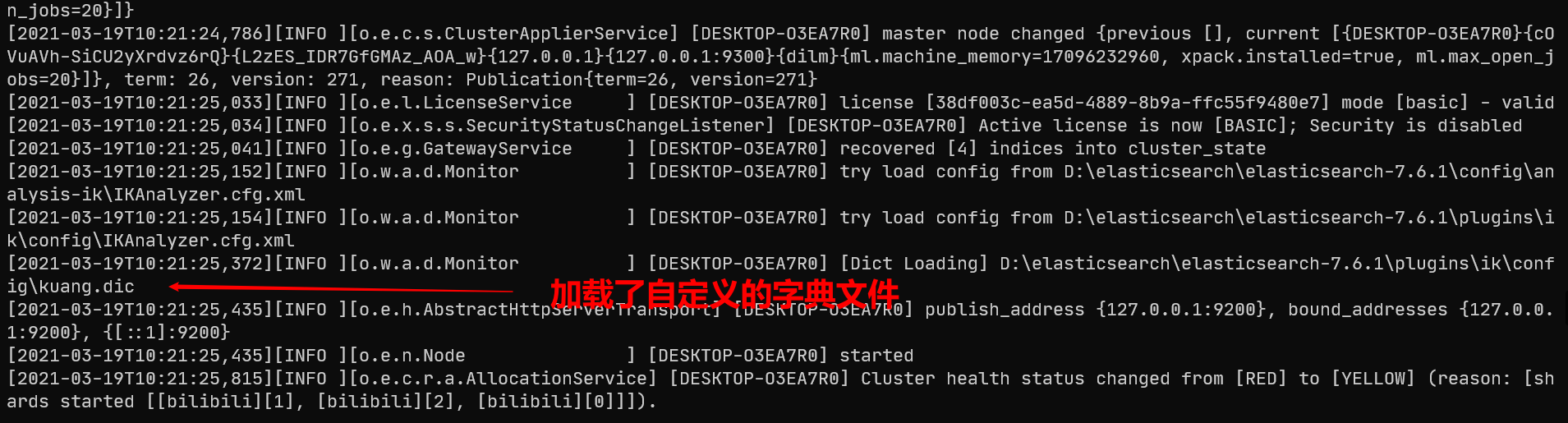
再次测试:
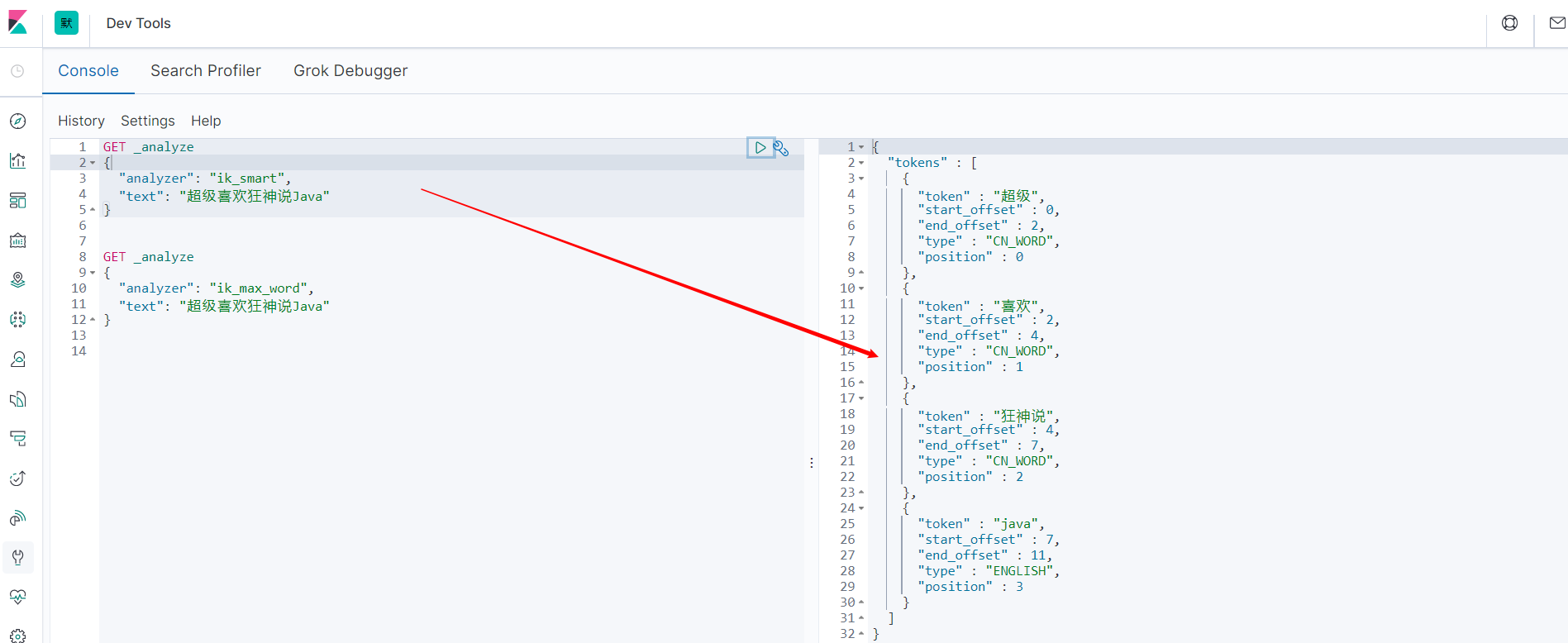
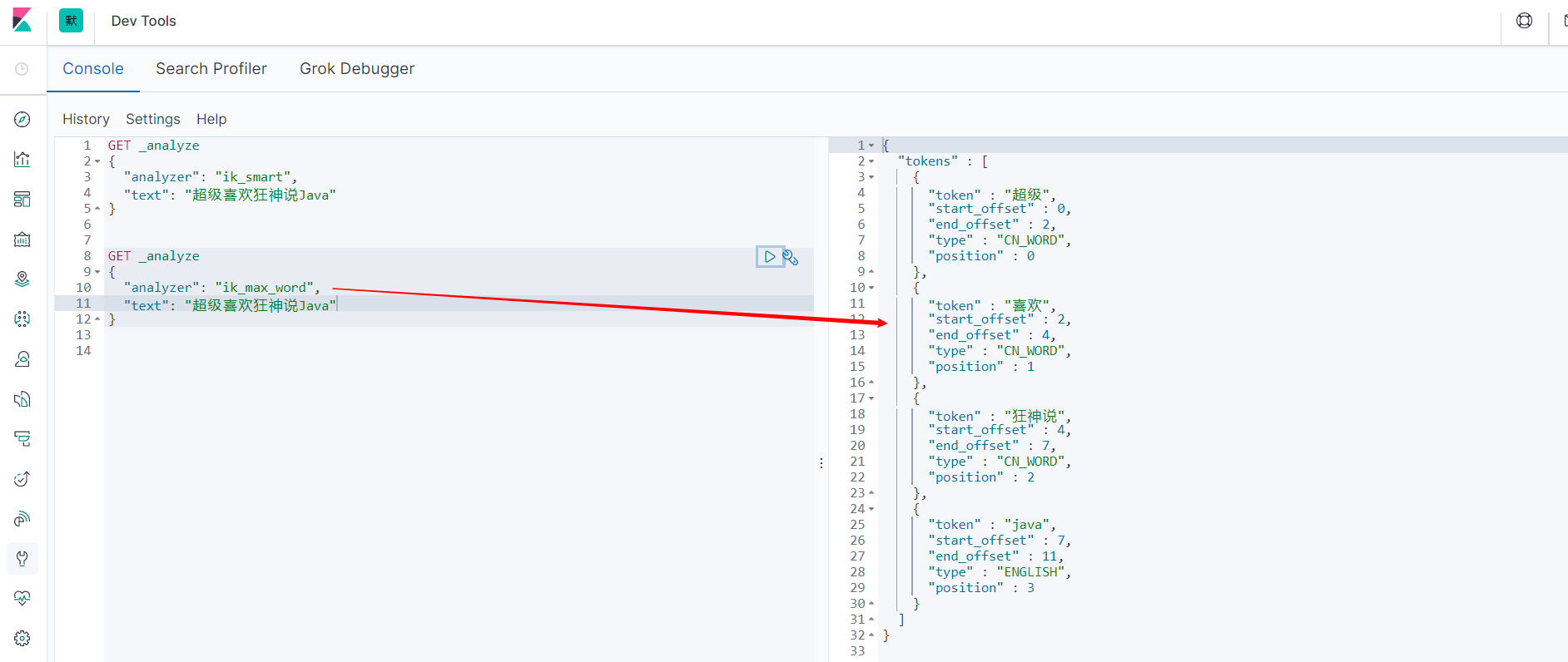
以后的话,我们需要自己配置分词就在自己定义的dic文件中进行配置即可。