二级缓存
二级缓存定义与需求分析
定义
二级缓存也称应用级缓存,与一级缓存不同的是它的作用范围是整个应用,而且可以跨线程。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。
需求分析
二级缓存是一个完整的缓存解决方案,那应该包含哪些功能呢?这里我们分为核心功能和非核心功能两类。
核心功能

其它功能
- 过期清理:指清理存放数据过久的数据。
- 线程安全:保证缓存可以被多个线程同时使用。
- 写安全:当拿到缓存数据后,可对其进行修改,而不影响原本的缓存数据。通常采取做法是对缓存对象进行深拷贝。
二级缓存组件结构
责任链设计
这么多的功能,如何才能简单的实现,并保证它的灵活性与扩展性呢?这里MyBatis抽象出Cache接口,其只定义了缓存中最基本的功能方法:
- 设置缓存。
- 获取缓存。
- 清除缓存。
- 获取缓存数量。
然后上述中每一个功能都会对应一个组件类,并基于装饰者加责任链的模式,将各个组件进行串联。在执行缓存的基本功能时,其它的缓存逻辑会沿着这个责任链依次往下传递。
这样设计有以下优点:
- 职责单一:各个节点只负责自己的逻辑,不需要关心其它节点。
- 扩展性强:可根据需要扩展节点、删除节点,还可以调换顺序保证灵活性。
- 松耦合:各节点之间没有强制依赖其它节点。而是通过顶层的Cache接口进行间接依赖。
组件结构
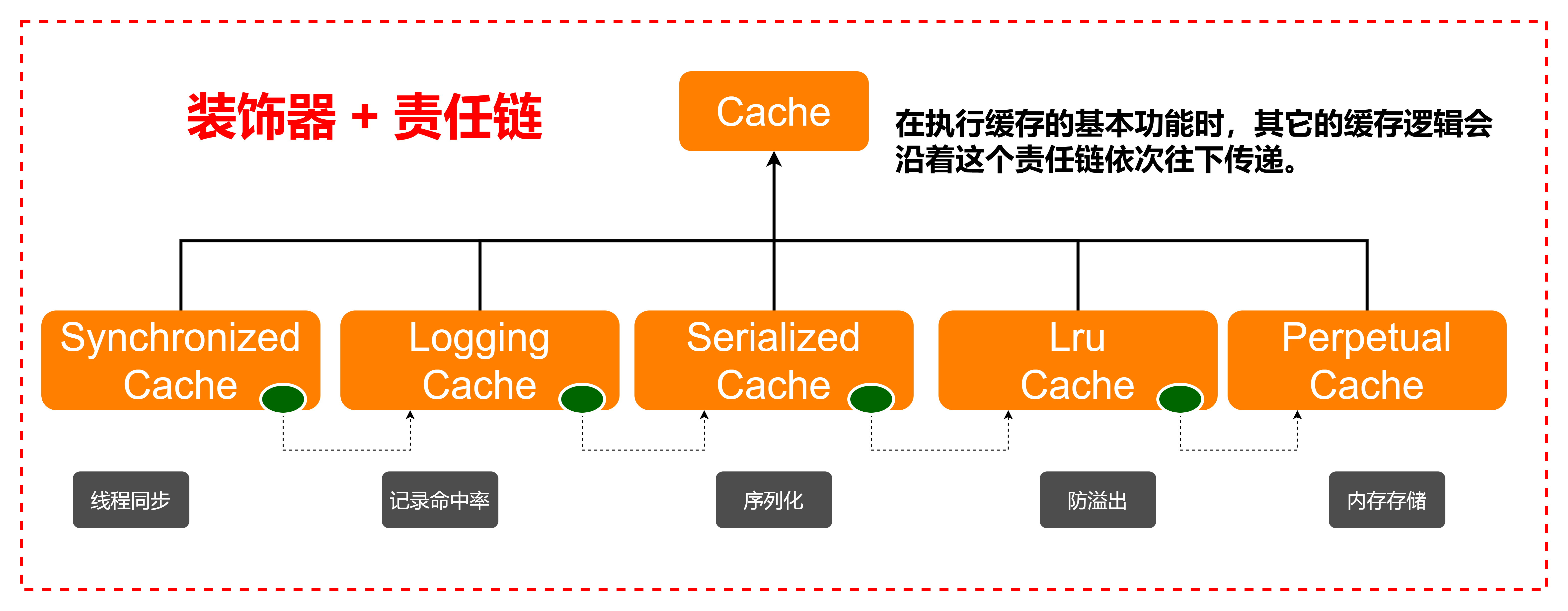
有一些组件没有配置的话,在使用的时候就没有。上图描述的是默认配置下会看到的调用组件。其中PerpetualCache就是我们在一级缓存中看到的那个用于存储一级缓存的HashMap。由此可以发现,二级缓存和一级缓存的存储用的是同一个组件实现,底层都是HashMap,存储于内存中。
二级缓存使用和命中
缓存空间声明
二级缓存默认是不开启的,需要为其声明缓存空间才可以使用,通过
@CacheNamespace或为指定的MappedStatement声明(mapper文件)。声明之后,该缓存为该Mapper所独有,其它Mapper不能访问。如需要多个Mapper共享一个缓存空间可通过@CacheNamespaceRef 或进行引用同一个缓存空间。
@CacheNamespace 详细配置见下表:
配置 说明 implementation 指定缓存的存储实现类,默认是用HashMap存储在内存当中 eviction 指定缓存溢出淘汰实现类,默认LRU ,清除最少使用 flushInterval 设置缓存定时全部清空时间,默认不清空 size 指定缓存容量,超出后就会按eviction指定算法进行淘汰 readWrite true即通过序列化复制,来保证缓存对象是可读写的,默认true blocking 为每个Key的访问添加阻塞锁,防止缓存击穿 properties 为上述组件,配置额外参数,key对应组件中的字段名。 缓存其它配置
@CacheNamespace 还可以通过其它参数来控制二级缓存。
| 字段 | 配置域 | 说明 |
|---|---|---|
| cacheEnabled | true | false | 二级缓存全局开关,默认开启 |
| useCache | select|update|insert|delete | 指定的statement是否开启,默认开启 |
| flushCache | select|update|insert|delete | 执行sql前是否清空当前二级缓存空间,update默认true。query默认false |
如果sql是用注解编写的,我们可以使用@Options注解配置。
@CacheNamespace
public interface UserMapper {
/**
* 根据ID查询用户
* @param id 用户ID
* @return 用户实体
*/
@Select("select * from user where id = #{id}")
@Options(useCache = true, flushCache = Options.FlushCachePolicy.TRUE)
User selectById(Integer id);
}
也可以在mapper文件中直接配置:
<!--注解和mapper文件用同一个二级缓存空间-->
<cache-ref namespace="com.sanfen.UserMapper"/>
<select id="selectById2" resultType="com.sanfen.User" useCache="true" flushCache="true">
select * from user where id = #{id}
</select>
@CacheNamespace使用注意点
注意:如果我们同时使用了注解@CacheNamespace和在mapper文件里面配置了<cache/>,它们不会使用同一个二级缓存空间。也就是说,在Mapper接口里面注解写的SQL不会走mapper xml文件里面sql的二级缓存。要想这两个文件中的sql使用同一个二级缓存空间,需要在mapper文件里面配置这样配置:
<!--注解和mapper文件用同一个二级缓存空间-->
<cache-ref namespace="com.sanfen.UserMapper"/>
二级缓存命中条件
二级缓存的命中场景与一级缓存类似,不同在于二级可以跨会话使用,还有就是二级缓存的更新,必须是在会话提交之后。
- 会话提交后。
- SQL语句、参数相同。
- 相同的statement。
- RowBounds相同。
除了第一个条件,其他和一级缓存是一样的。通过上面的组件结构,我们可以发现二级缓存和一级缓存使用的是同一个存储实现类,而且它们的缓存key也很相似。
为什么要提交之后才能命中缓存?
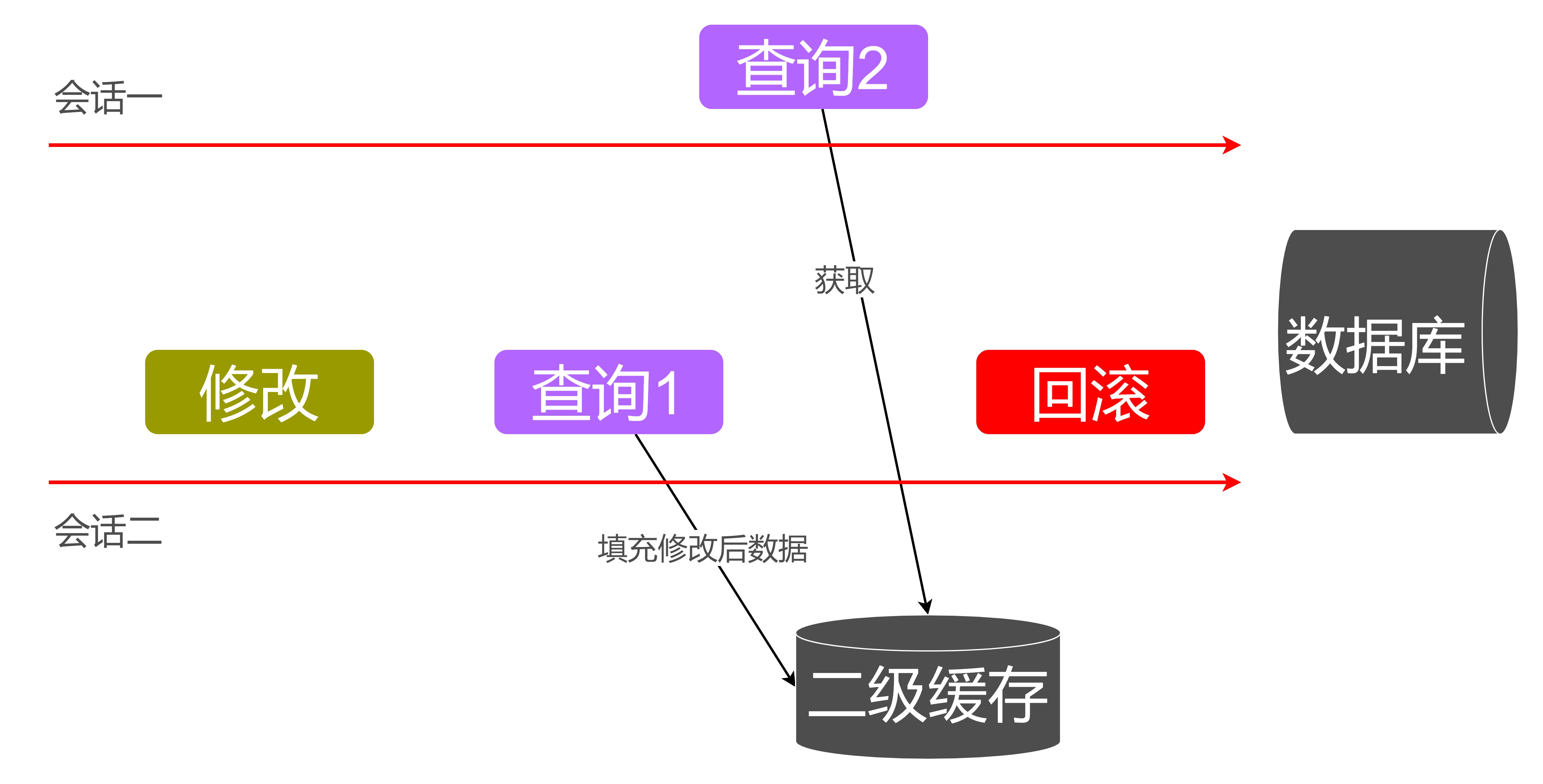
- 如上图两个会话在修改同一数据,当会话二修改后,在将其查询出来,假如它实时填充到二级缓存,而会话一就能过缓存获取修改之后的数据,但实质是修改的数据回滚了,并没真正的提交到数据库。
- 所以为了保证数据一致性,二级缓存必须是
会话提交之才会真正填充,包括对缓存的清空,也必须是会话正常提交之后才生效。因为提交之后,就不能回滚了,事务就完成了。事务的持久性,已经提交,修改就是永久的。
二级缓存源码分析
二级缓存结构
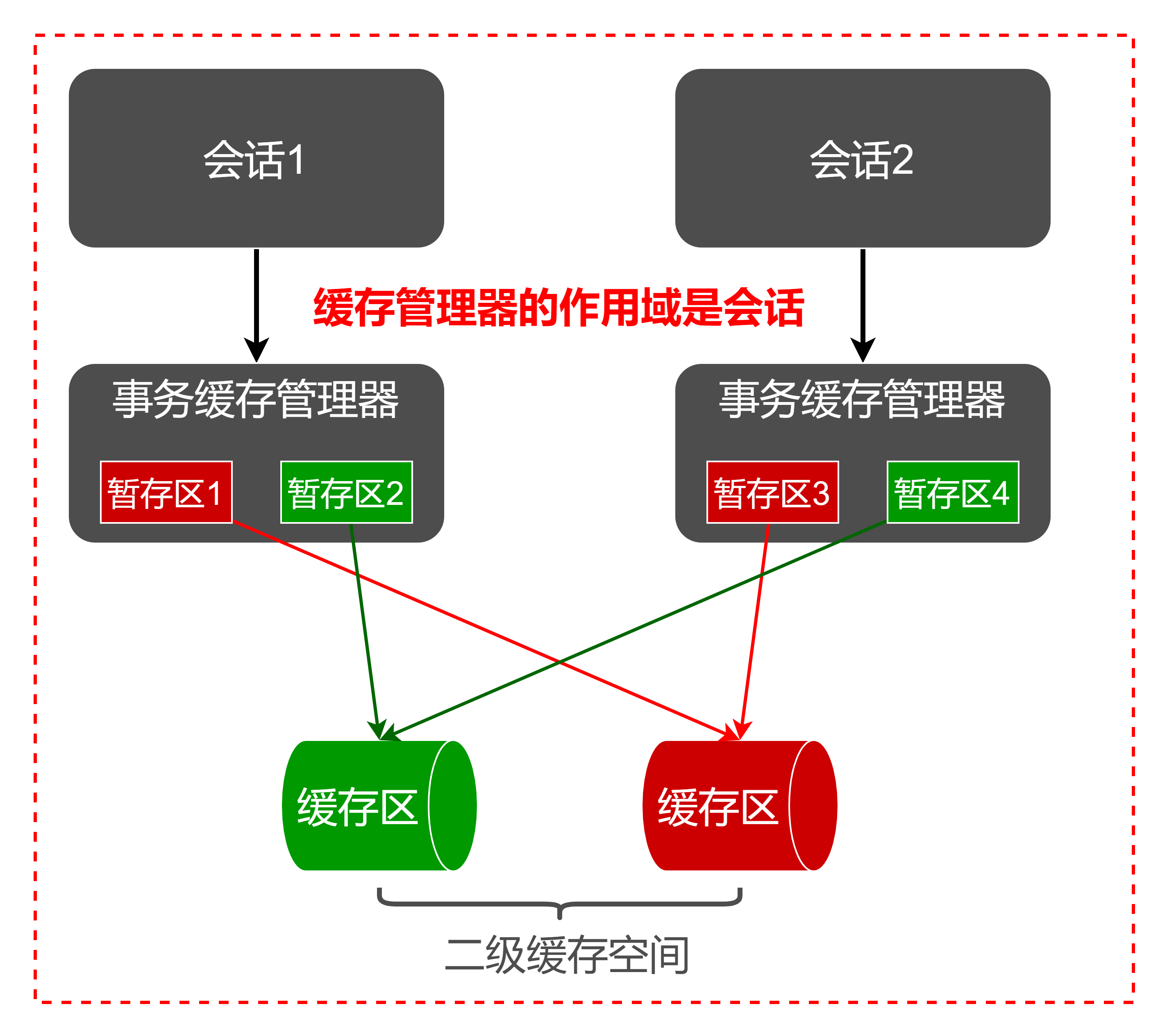
为了实现会话提交之后才变更二级缓存,MyBatis为每个会话设立了若干个暂存区,当前会话对指定缓存空间的变更,都存放在对应的暂存区,当会话提交之后才会提交到每个暂存区对应的缓存空间。为了统一管理这些暂存区,每个会话都一个唯一的事务缓存管理器。所以这里暂存区也可叫做事务缓存。
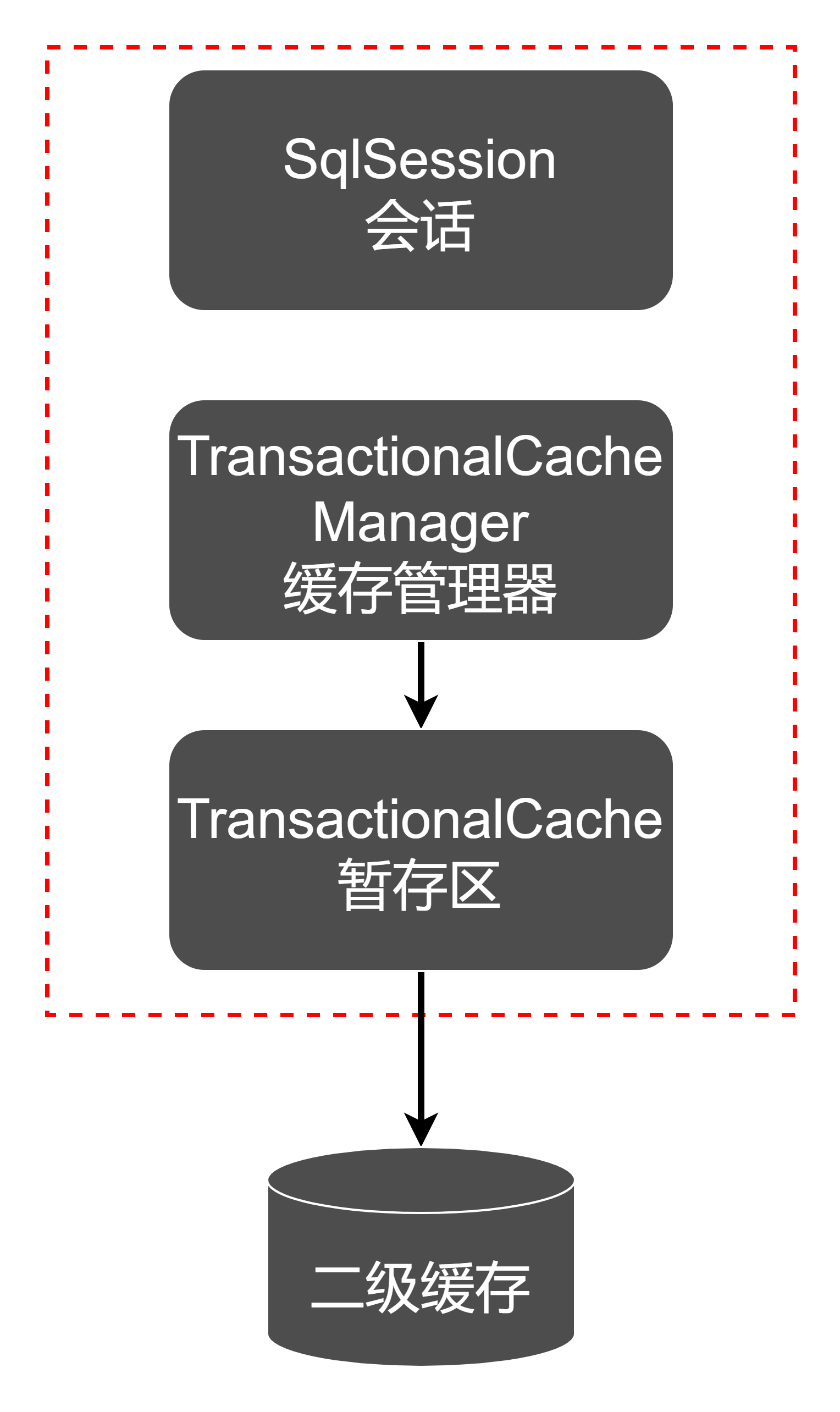
会话、暂存区、二级缓存空间的关系
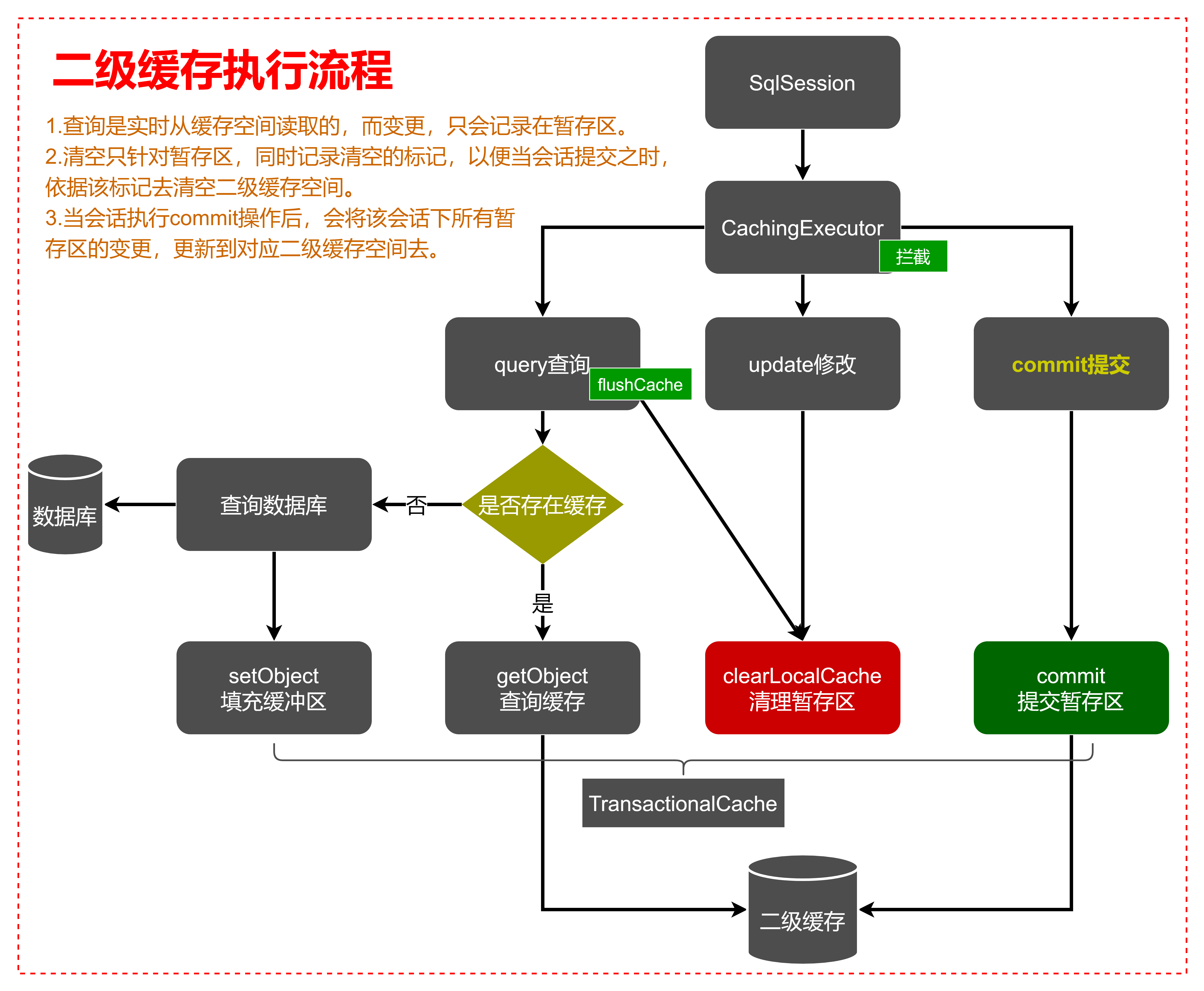
二级缓存的存取流程
原本会话是通过Executor实现SQL调用,这里基于装饰器模式使用CachingExecutor对SQL调用逻辑进行拦截。以嵌入二级缓存相关逻辑。
查询操作query:当会话调用query() 时,会基于查询语句、参数等数据组成缓存Key,然后尝试从二级缓存中读取数据。读到就直接返回,没有就调用被装饰的Executor去查询数据库,然后在填充至对应的暂存区。
请注意,这里的
查询是实时从缓存空间读取的,而变更,只会记录在暂存区。更新操作update:当执行update操作时,同样会基于查询的语句和参数组成缓存KEY,然后在执行update之前清空缓存。这里
清空只针对暂存区,同时记录清空的标记,以便当会话提交之时,依据该标记去清空二级缓存空间。如果在查询操作中配置了flushCache=true ,也会执行相同的操作。
提交操作commit:当会话执行commit操作后,会将该会话下所有暂存区的变更,更新到对应二级缓存空间去。
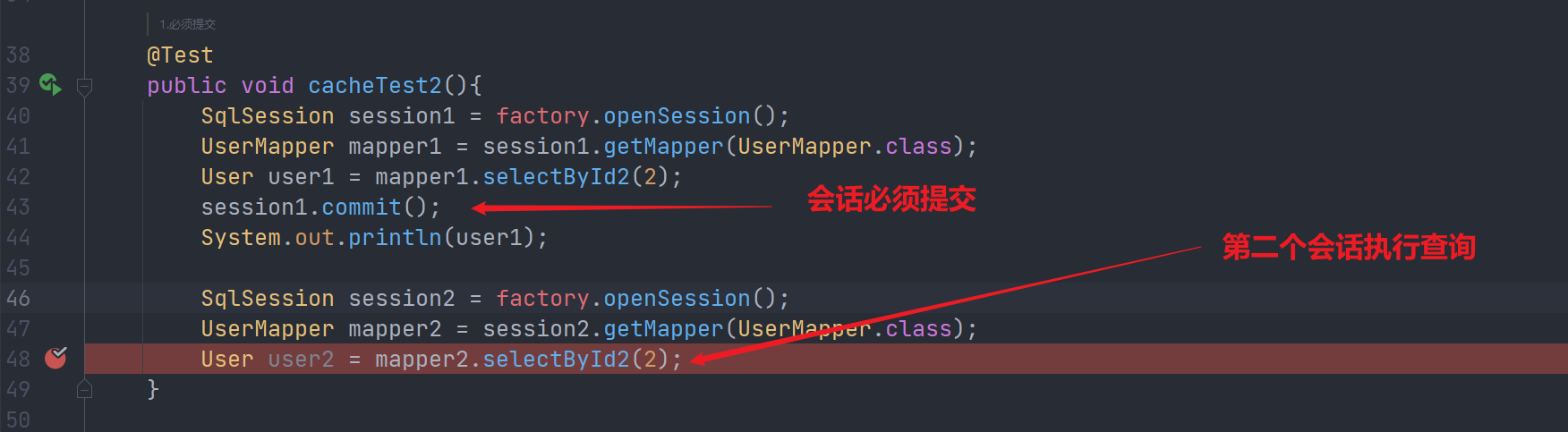
debug二级缓存命中情况
/**
* 1.必须提交
*/
@Test
public void cacheTest2(){
SqlSession session1 = factory.openSession();
UserMapper mapper1 = session1.getMapper(UserMapper.class);
User user1 = mapper1.selectById2(2);
session1.commit();
System.out.println(user1);
SqlSession session2 = factory.openSession();
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user2 = mapper2.selectById2(2);
}
确保二级缓存配置已经打开。
分别在第二次查询和CachingExecutor的query方法打断点:
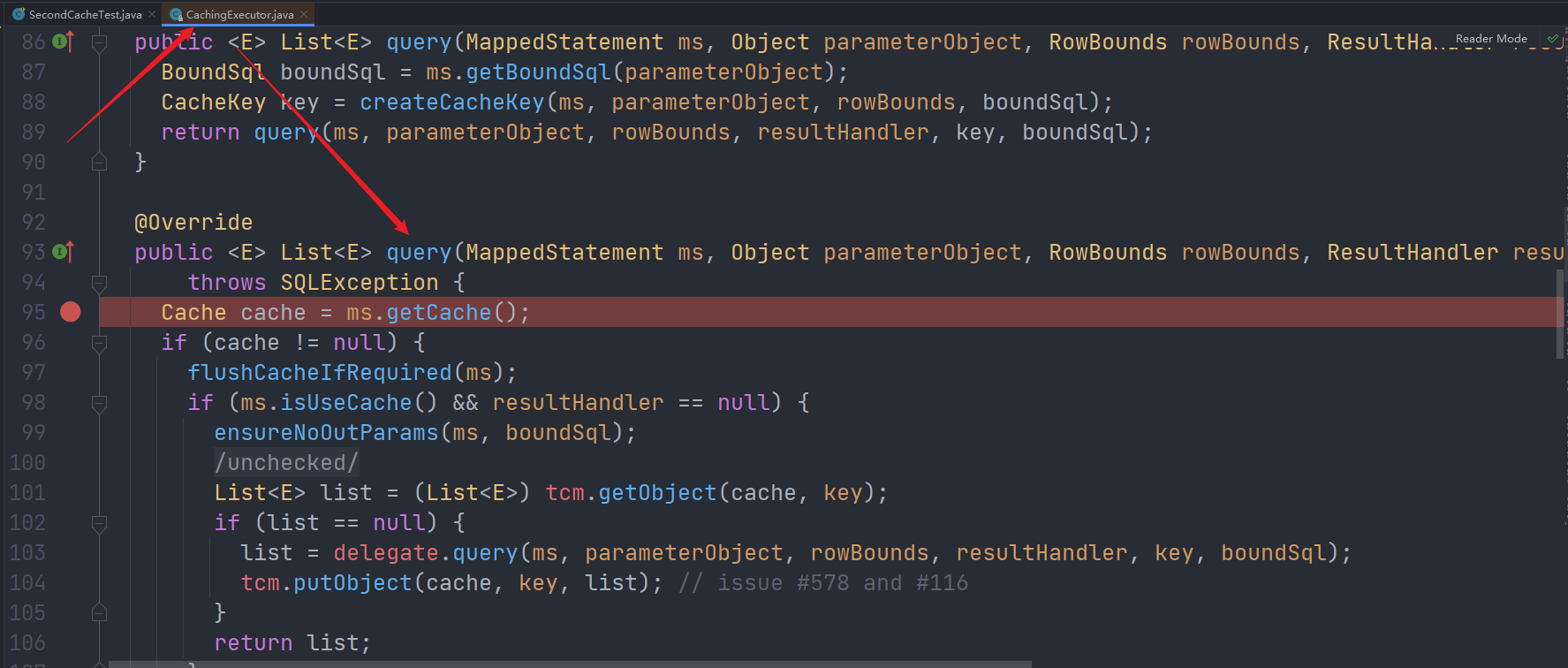
每次查询都是会经过二级缓存的,也就是会进入CachingExecutor的query()方法。所以先让第一次查询放行。
1.第二次查询,进入
CachingExecutor的query()方法。
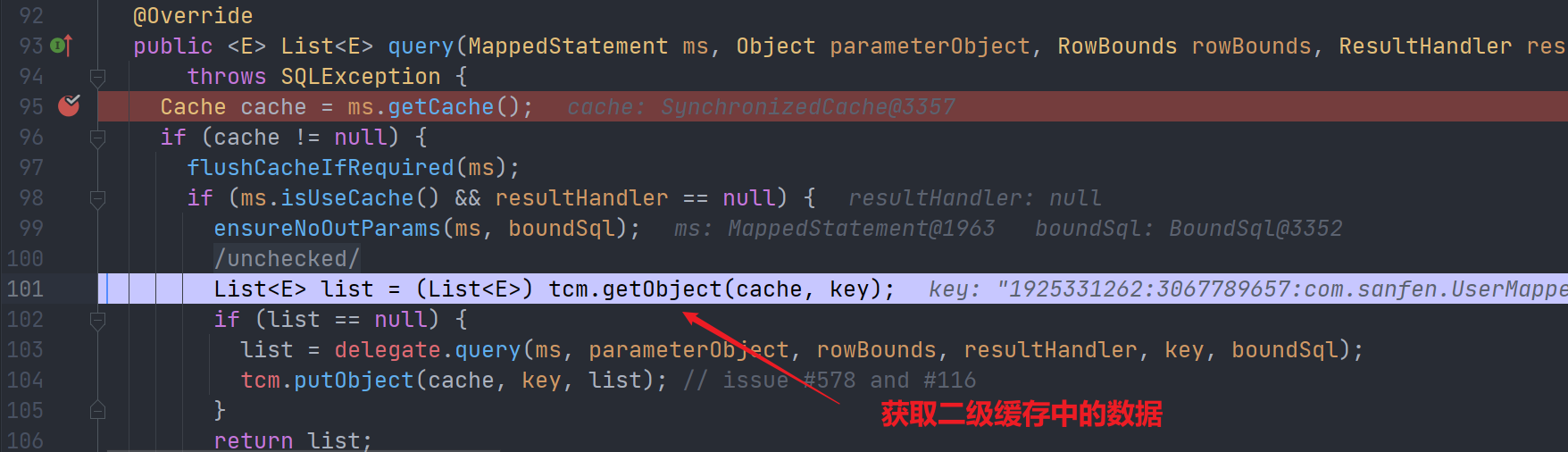
而且我们观察cache变量,可以发现二级缓存使用的装饰器+责任链:
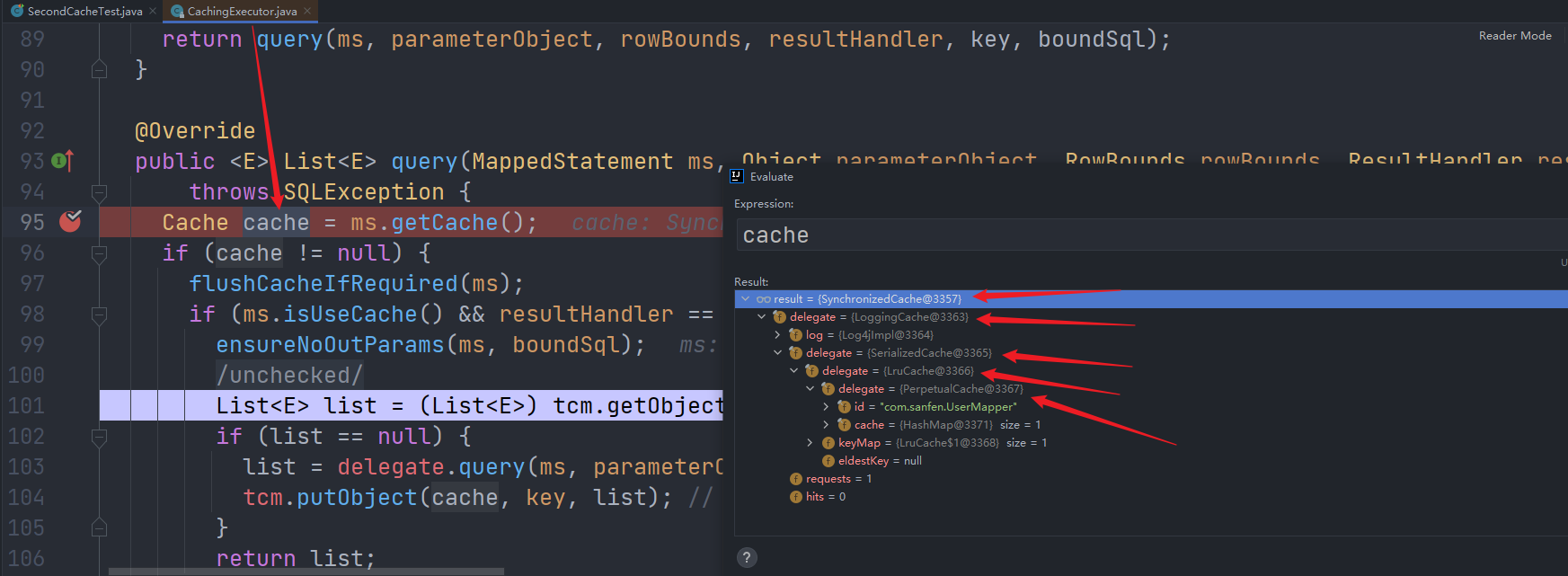
我们没有添加其他的配置,是默认的组件。如果我们修改了配置,会有更多的组件。比如:
BlockingCache: 使用ReentrantLock来防止高速缓存未命中时对数据库的大规模访问,它设置了对高速缓存键的锁定
ScheduledCache:设置定时刷新缓存。
接下来进入获取二级缓存的逻辑。
2.
TransactionalCacheManager的getObject()方法。这里是缓存管理器,接下来会进入暂存区。
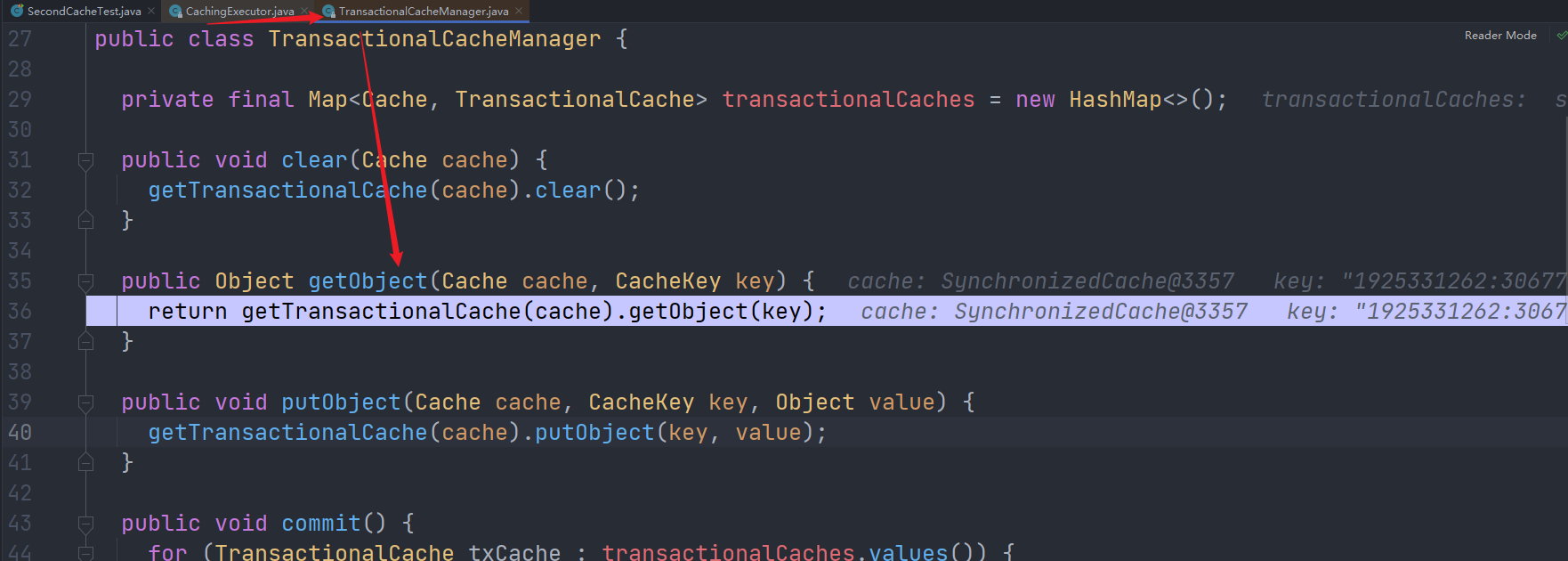
3.
TransactionalCache的getObject()方法。这里是暂存区。因为是查询,所以会直接从二级缓存空间进行读取。接下来就是责任链调用装饰器对象。
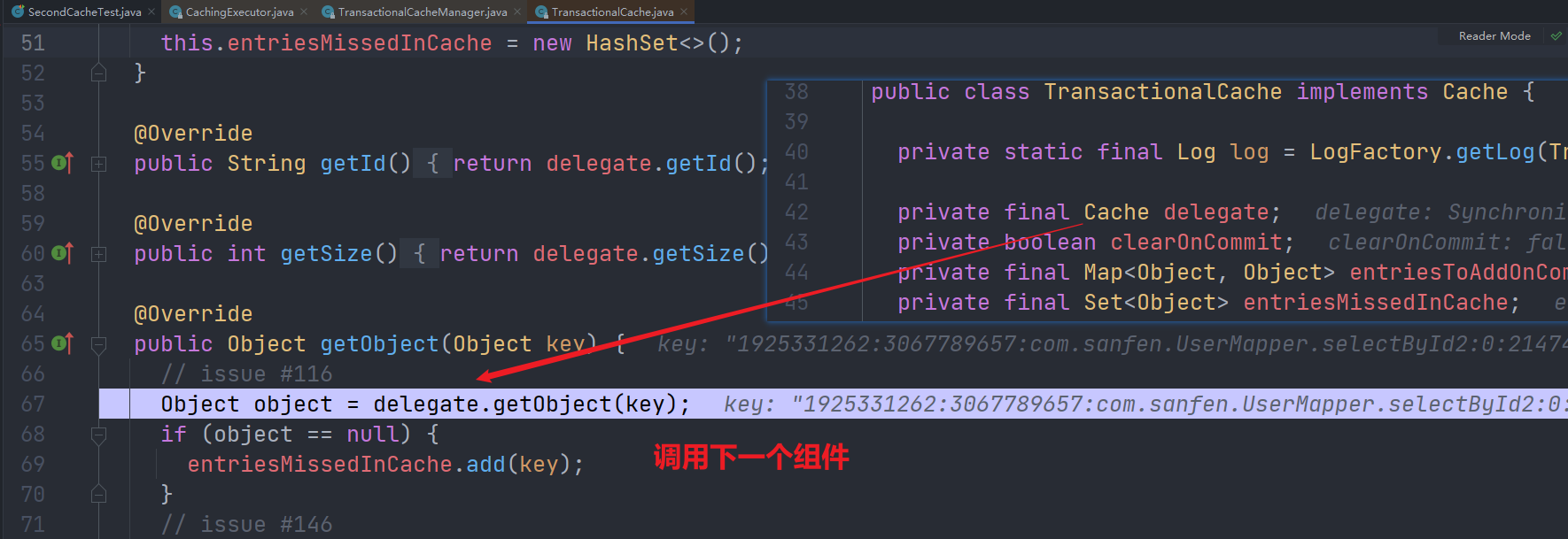
4.进入责任链调用。
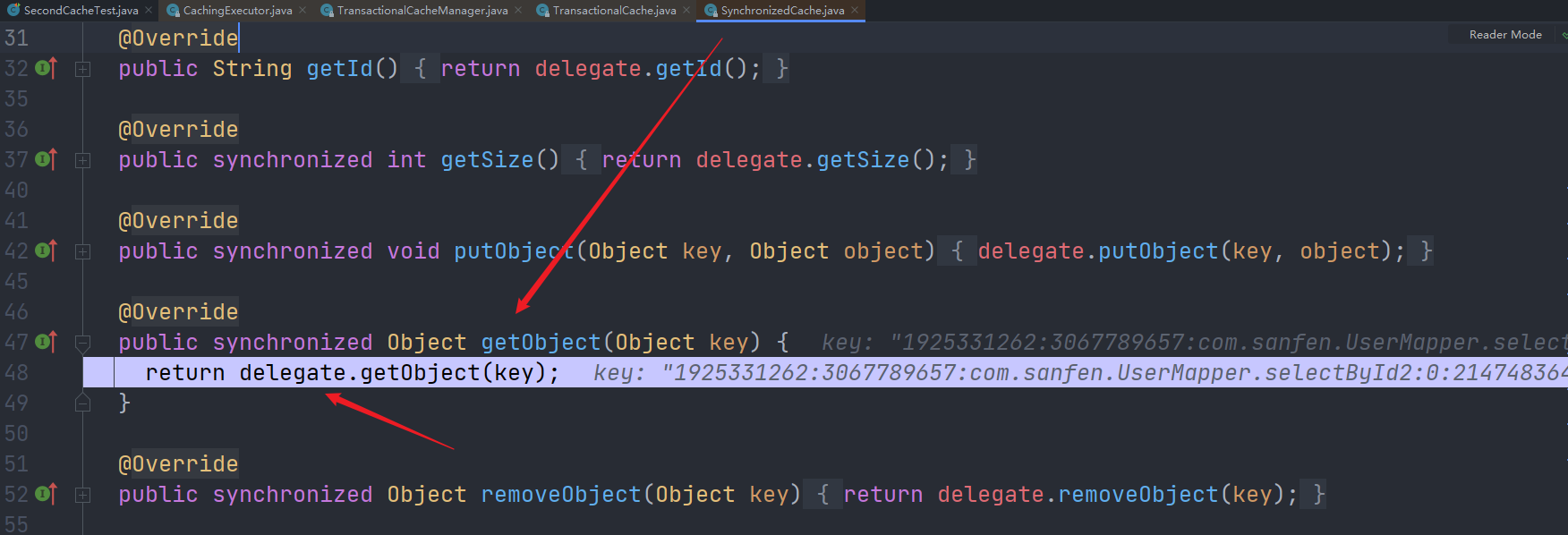
首先是SynchronizedCache:
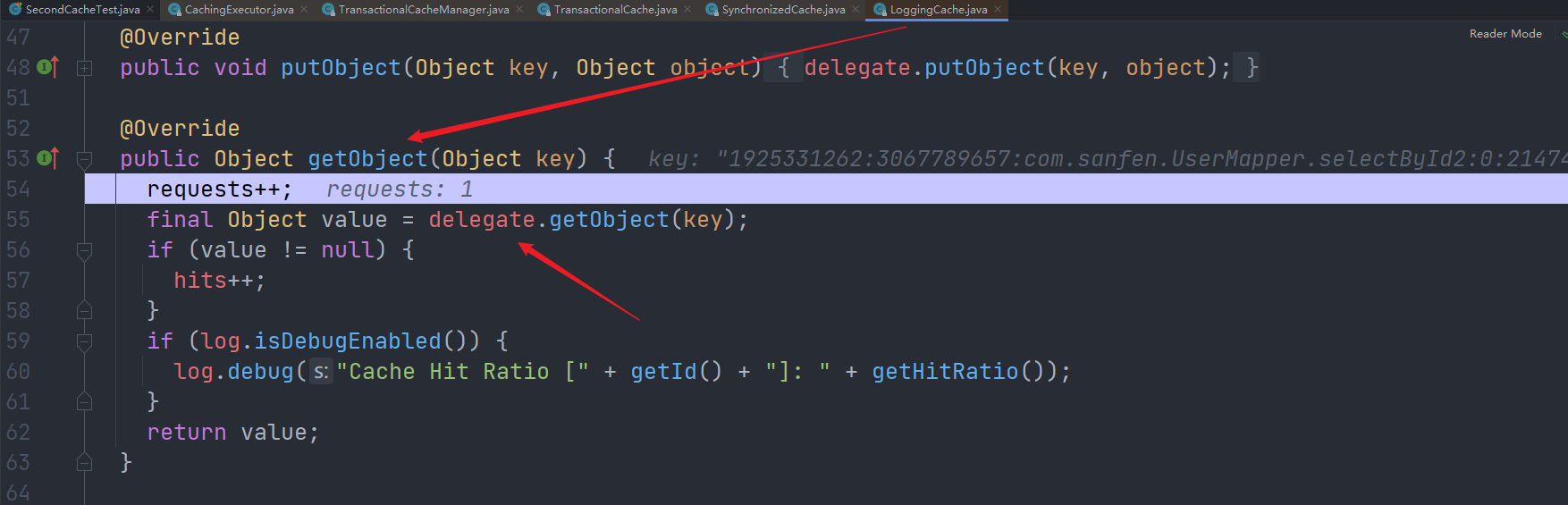
然后是LoggingCache:
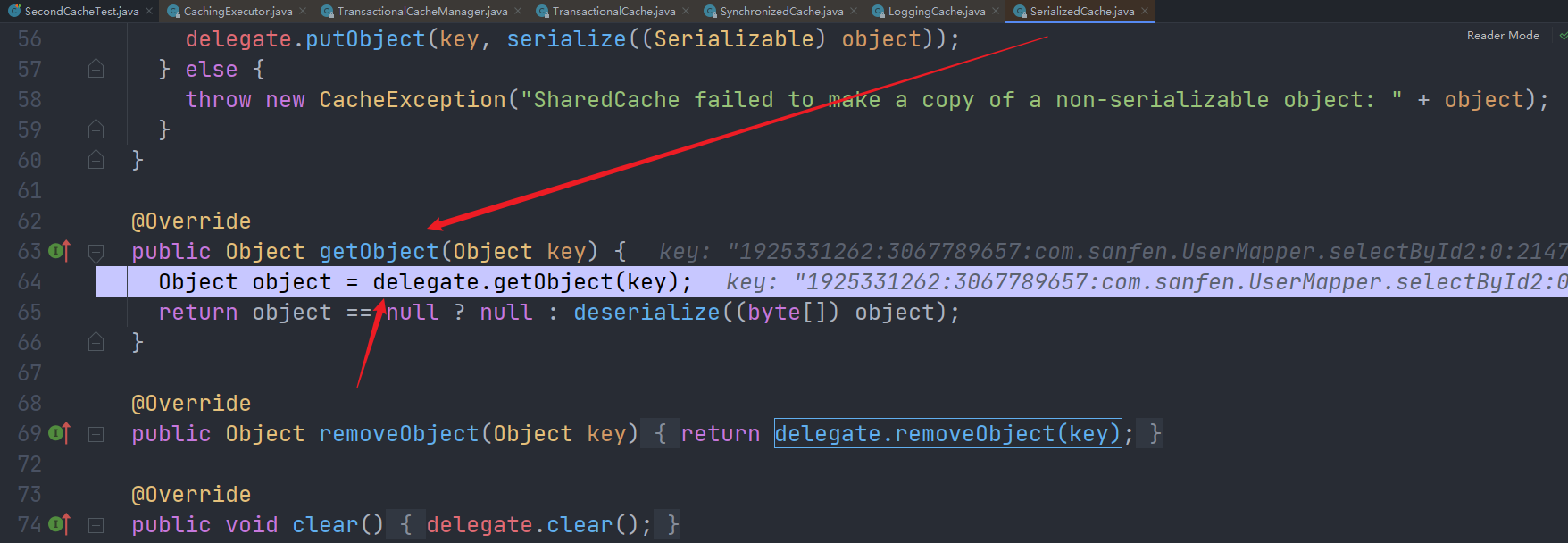
然后是SerializedCache:
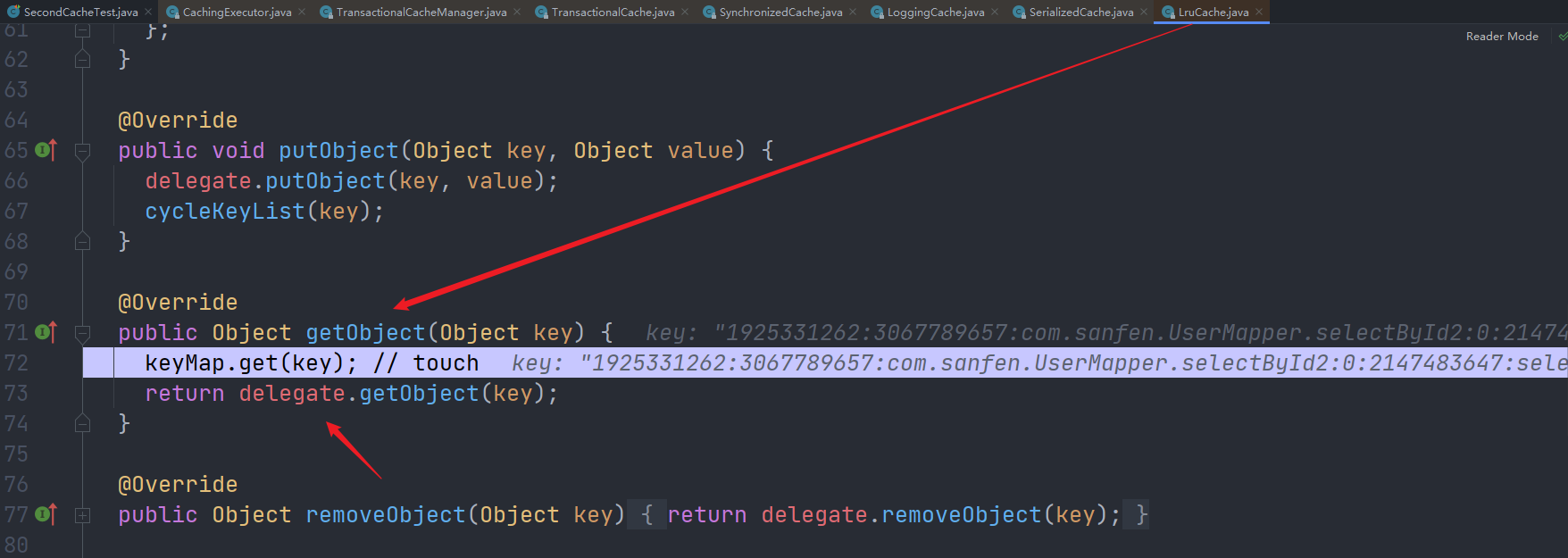
然后是LruCache:
然后是PerpetualCache,这里是真正存储的逻辑。和一级缓存差不多,把数据存于内存中的HashMap中。
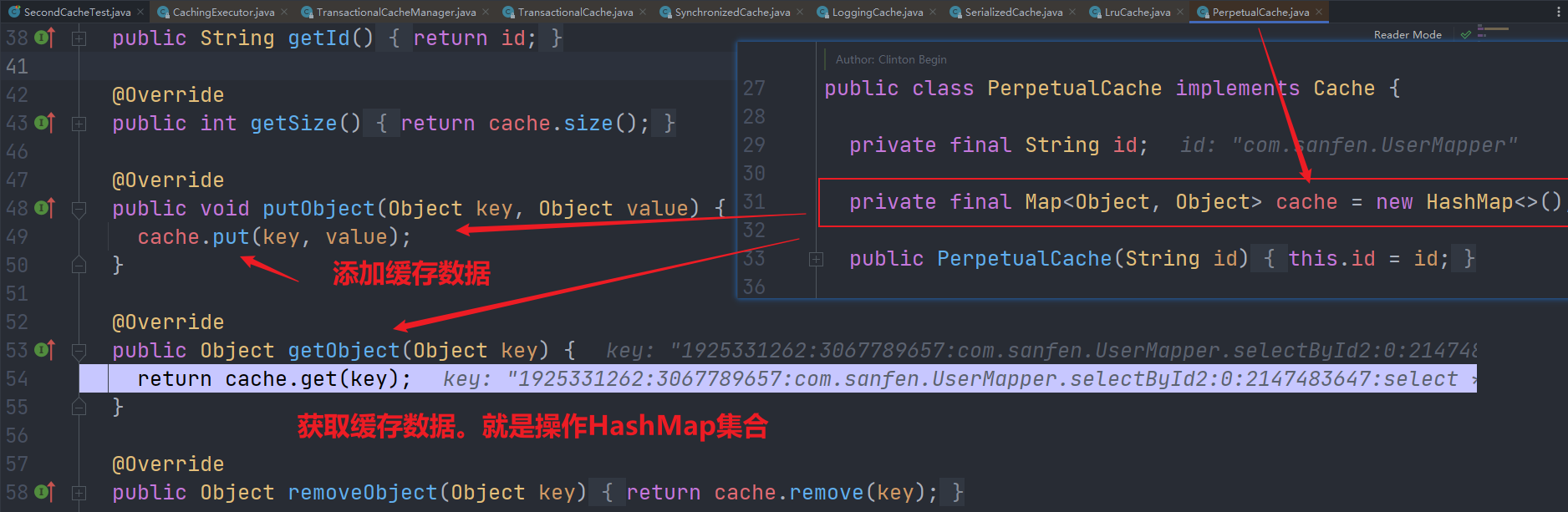
由此可以发现,二级缓存的底层存储逻辑是操作HashMap。而且和一级缓存存储的时候用的是同一个类。二级缓存和一级缓存就是规则和命中条件不一样,底层的存储结构是一样的。